6 Extraction Speed Considerations
Before you start
In this chapter, we learn how to parallelize raster data extraction for polygons data. We do not cover parallelization of raster data extraction for points data because it is very fast. Thus, the repeated raster data extractions for points is unlikely to be a bottleneck in your work. We first start with parallelizing data extraction from a single-layer raster data. We then move on to a multi-layer raster data case.
There are different ways of parallelizing the same extraction process. We will discuss several parallelization approaches in terms of their speed and memory footprint. You will learn how to parallelize matters. A naive parallelization can actually increase the time of raster data extraction, while a clever parallelization approach can save you hours or even days (depending on the size of the extraction job, of course).
We will use the future.apply and parallel packages for parallelization. Basic knowledge of parallelization using these packages is assumed. Those who are not familiar with parallelized looping using lapply() and parallelization using mclapply() (Mac and Linux users only) or future_lapply() (including Windows), see Chapter A first.
Direction for replication
Datasets
All the datasets that you need to import are available here. In this chapter, the path to files is set relative to my own working directory (which is hidden). To run the codes without having to mess with paths to the files, follow these steps:
- set a folder (any folder) as the working directory using
setwd()
- create a folder called “Data” inside the folder designated as the working directory (if you have created a “Data” folder previously, skip this step)
- download the pertinent datasets from here
- place all the files in the downloaded folder in the “Data” folder
Warning: the folder includes a series of daily PRISM datasets stored by month for 10 years. They amount to \(12.75\) GB of data.
Packages
Run the following code to install or load (if already installed) the pacman package, and then install or load (if already installed) the listed package inside the pacman::p_load() function.
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
parallel, # for parallelization
future.apply, # for parallelization
terra, # handle raster data
raster, # handle raster data
exactextractr, # fast extractions
sf, # vector data operations
dplyr, # data wrangling
data.table, # data wrangling
prism # download PRISM data
)6.1 Single raster layer
Let’s prepare for parallel processing for the rest of the section.
library(parallel)
#--- get the number of logical cores to use ---#
(
num_cores <- detectCores() - 1
)[1] 196.1.1 Datasets
We will use the following datasets:
-
raster: Iowa Cropland Data Layer (CDL) data in 2015
- polygons: Regular polygon grids over Iowa
Iowa CDL data in 2015
#--- Iowa CDL in 2015 ---#
(
IA_cdl_15 <- rast("Data/IA_cdl_2015.tif")
)class : SpatRaster
dimensions : 11671, 17795, 1 (nrow, ncol, nlyr)
resolution : 30, 30 (x, y)
extent : -52095, 481755, 1938165, 2288295 (xmin, xmax, ymin, ymax)
coord. ref. : +proj=aea +lat_0=23 +lon_0=-96 +lat_1=29.5 +lat_2=45.5 +x_0=0 +y_0=0 +datum=NAD83 +units=m +no_defs
source : IA_cdl_2015.tif
color table : 1
name : IA_cdl_2015
min value : 0
max value : 229 Values recorded in the raster data are integers representing land use type.
Regularly-sized grids over Iowa
#--- regular grids over Iowa ---#
(
IA_grids <-
tigris::counties(state = "IA", cb = TRUE) %>%
#--- create regularly-sized grids ---#
st_make_grid(n = c(50, 50)) %>%
#--- project to the CRS of the CDL data ---#
st_transform(terra::crs(IA_cdl_15))
)Geometry set for 2500 features
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: -53758.56 ymin: 1929065 xmax: 492975.7 ymax: 2293208
Projected CRS: unnamed
First 5 geometries:Here is how they look (Figure 6.1):
tm_shape(IA_cdl_15) +
tm_raster(title = "Land Use ") +
tm_shape(IA_grids) +
tm_polygons(alpha = 0) +
tm_layout(legend.outside = TRUE)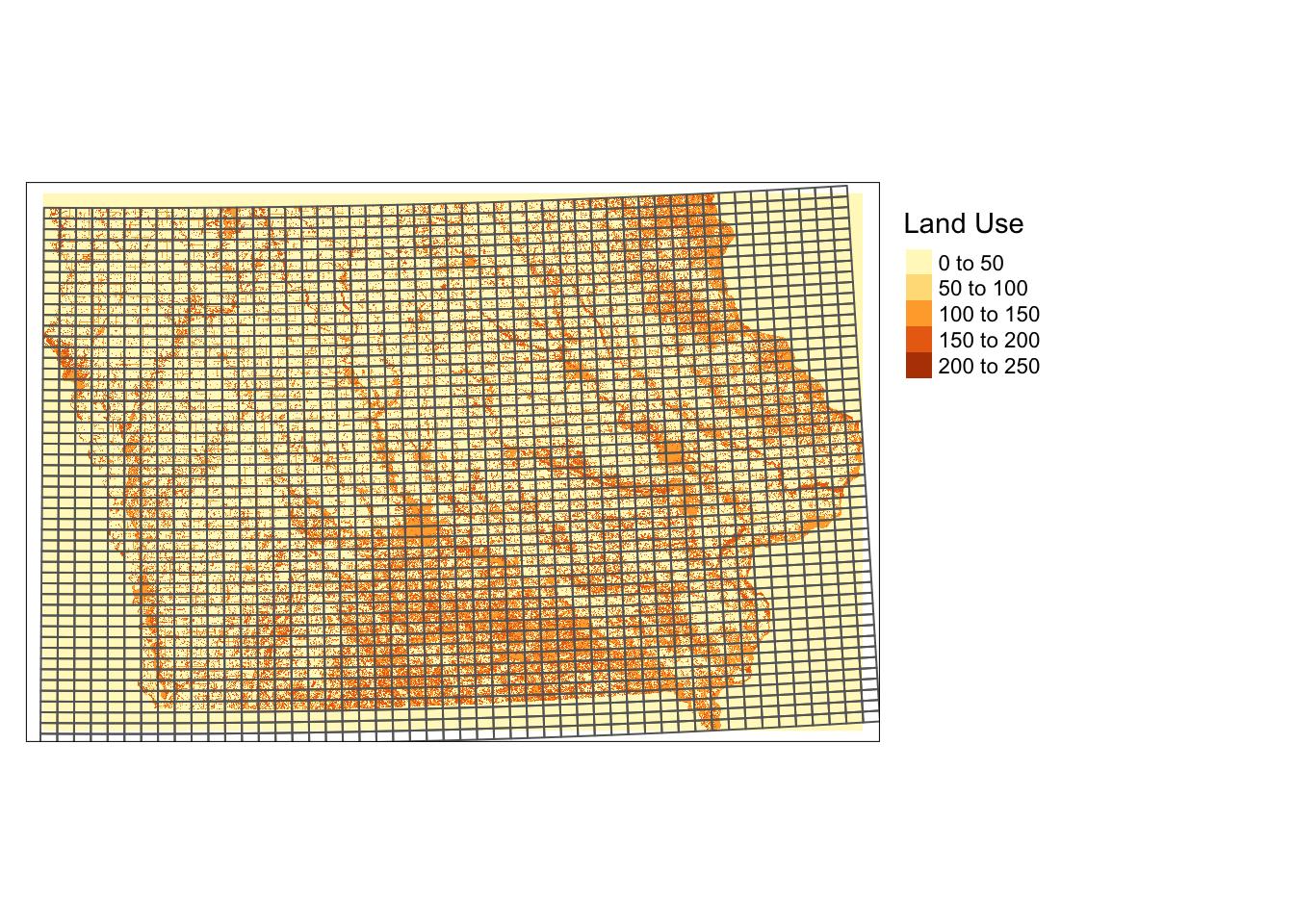
Figure 6.1: Regularly-sized grids and land use type in Iowa in 2105
6.1.2 Parallelization
Here is how long it takes to extract raster data values for the polygon grids using exact_extract().
tic()
temp <- exact_extract(IA_cdl_15, IA_grids)
toc()elapsed
11.491 One way to parallelize this process is to let each core work on one polygon at a time. Let’s first define the function to extract values for one polygon and then run it for all the polygons parallelized.
#--- function to extract raster values for a single polygon ---#
get_values_i <- function(i) {
temp <- exact_extract(IA_cdl_15, IA_grids[i, ])
return(temp)
}
#--- parallelized ---#
tic()
temp <- mclapply(1:nrow(IA_grids), get_values_i, mc.cores = num_cores)
toc()elapsed
89.721 As you can see, this is a terrible way to parallelize the computation process. To see why, let’s look at the computation time of extracting from one polygon, two polygons, and up to five polygons.
library(microbenchmark)
mb <- microbenchmark(
"p_1" = {
temp <- exact_extract(IA_cdl_15, IA_grids[1, ])
},
"p_2" = {
temp <- exact_extract(IA_cdl_15, IA_grids[1:2, ])
},
"p_3" = {
temp <- exact_extract(IA_cdl_15, IA_grids[1:3, ])
},
"p_4" = {
temp <- exact_extract(IA_cdl_15, IA_grids[1:4, ])
},
"p_5" = {
temp <- exact_extract(IA_cdl_15, IA_grids[1:5, ])
},
times = 100
)
mb %>%
data.table() %>%
.[, expr := gsub("p_", "", expr)] %>%
ggplot(.) +
geom_boxplot(aes(y = time / 1e9, x = expr)) +
ylim(0, NA) +
ylab("seconds") +
xlab("number of polygons to process")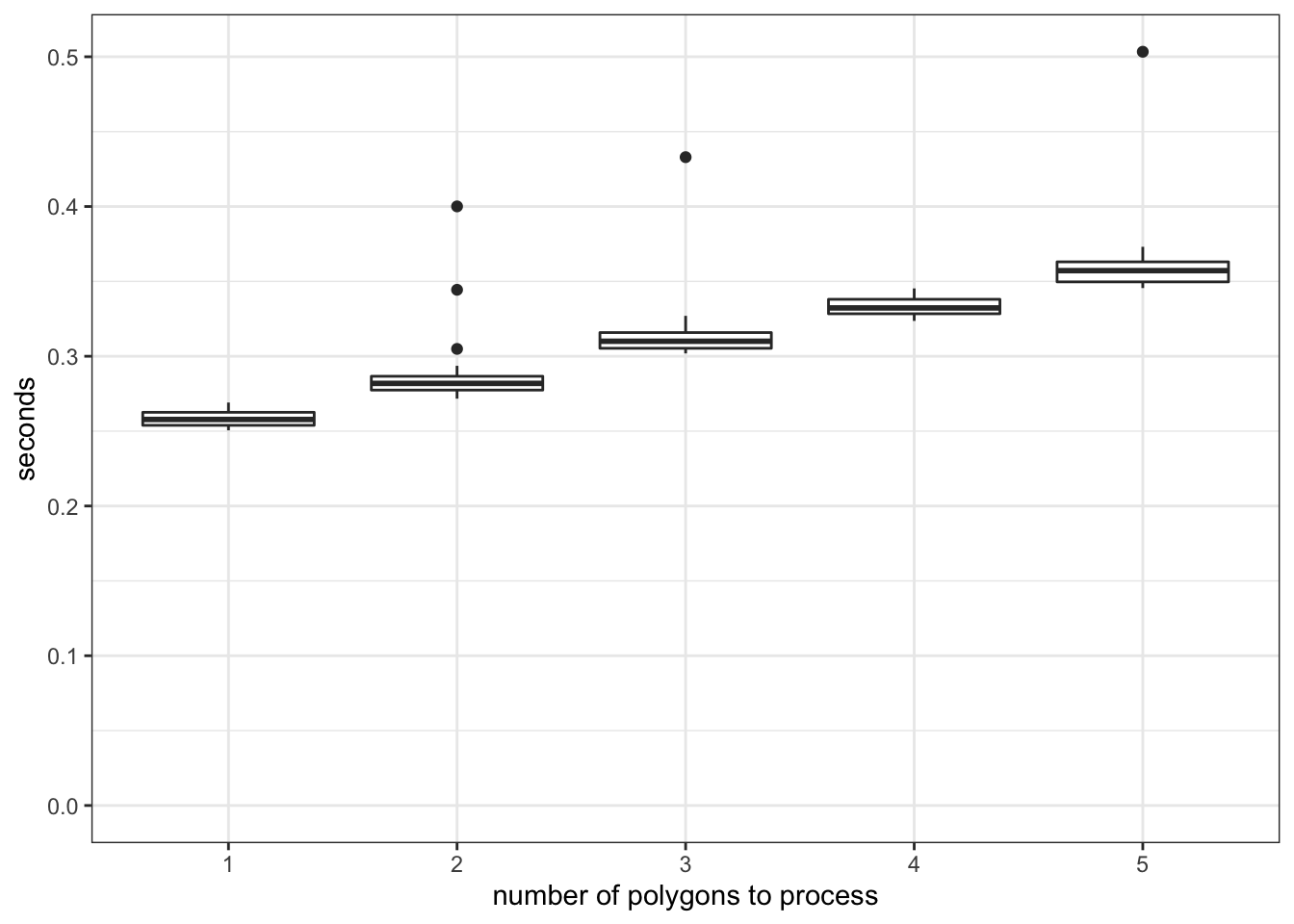
Figure 6.2: Comparison of the computation time of raster data extractions
As you can see in Figure 6.2, there is a significant overhead (about 0.23 seconds) irrespective of the number of the polygons to extract data for. Once the process is initiated and ready to start extracting values for polygons, it does not spend much time processing for additional units of polygon. So, this is a typical example of how you should NOT parallelize. Since each core processes about \(136\) polygons, a very simple math suggests that you would spend at least 31.28 (0.23 \(\times\) 136) seconds just for preparing extraction jobs.
We can minimize this overhead as much as possible by having each core use exact_extract() only once in which multiple polygons are processed in the single call. Specifically, we will split the collection of the polygons into 19 groups and have each core extract for one group.
#--- number of polygons in a group ---#
num_in_group <- floor(nrow(IA_grids) / num_cores)
#--- assign group id to polygons ---#
IA_grids <- IA_grids %>%
mutate(
#--- create grid id ---#
grid_id = 1:nrow(.),
#--- assign group id ---#
group_id = grid_id %/% num_in_group + 1
)
tic()
#--- parallelized processing by group ---#
temp <- mclapply(
1:num_cores,
function(i) exact_extract(IA_cdl_15, filter(IA_grids, group_id == i)),
mc.cores = num_cores
)
toc()elapsed
11.901 Great, this is much better.81
Now, we can further reduce the processing time by reducing the size of the object that is returned from each core to be collated into one. In the code above, each core returns a list of data.frames where each grid of the same group has multiple values from the intersecting raster cells.
#--- take a look at the the values extracted for the 1st polygon of the 1st group---#
head(temp[[1]][[1]])[1] "Error in h(simpleError(msg, call)) : \n error in evaluating the argument 'y' in selecting a method for function 'exact_extract': no applicable method for 'filter' applied to an object of class \"c('sfc_POLYGON', 'sfc')\"\n"
#--- the size of the list of data returned by the first core ---#
object.size(temp[[1]]) %>% format(units = "GB")[1] "0 Gb"In total, about 3GB of data has to be collated into one list from 19 cores. It turns out, this process is costly. To see this, take a look at the following example where the same exact_extrct() processes are run, yet nothing is returned by each core.
#--- define the function to extract values by block of polygons ---#
extract_by_group <- function(i) {
temp <- exact_extract(IA_cdl_15, filter(IA_grids, group_id == i))
#--- returns nothing! ---#
return(NULL)
}
#--- parallelized processing by group ---#
tic()
temp <- mclapply(
1:num_cores,
function(i) extract_by_group(i),
mc.cores = num_cores
)
toc()elapsed
6.689 Approximately 5.212 seconds were used just to collect the 3GB worth of data from the cores into one.
In most cases, we do not have to carry around all the individual cell values of landuse types for our subsequent analysis. For example, in Demonstration 3 (Chapter 1.3) we just need a summary (count) of each unique landuse type by polygon. So, let’s get the summary before we have the computer collect the objects returned from each core as follows:
extract_by_group_reduced <- function(i) {
temp_return <- exact_extract(
IA_cdl_15,
filter(IA_grids, group_id == i)
) %>%
#--- combine the list of data.frames into one with polygon id ---#
rbindlist(idcol = "id_within_group") %>%
#--- find the count of land use type values by polygon ---#
.[, .(num_value = .N), by = .(value, id_within_group)]
return(temp_return)
}
tic()
#--- parallelized processing by group ---#
temp <- mclapply(
1:num_cores,
function(i) extract_by_group_reduced(i),
mc.cores = num_cores
)
toc()elapsed
8.514 It is of course slower than the one that returns nothing, but it is much faster than the one that does not reduce the size before the outcome collation.
As you can see, the computation time of the fastest approach is now much less, but you still only gained 81.21. How much time did I spend writing the code to do the parallelized group processing? Three minutes. Obviously, what matters to you is the total time (coding time plus processing time) you spend to get the desired outcome. Indeed, the time you could save by a clever coding at the most is 89.72 seconds. Writing any kind of code in an attempt to make your code faster takes more time than that. So, don’t even try to make your code faster if the processing time is quite short in the first place. Before you start parallelizing things, go through what you need to go through in terms of coding in your head, and judge if it’s worth it or not.
Imagine processing CDL data for all the states from 2009 to 2020. Then, the whole process will take roughly 15.25 (\(51 \times 12 \times 89.721/60/60\)) hours. Again, a super rough calculation tells us that the whole process would be done in 1.45 hours if parallelized in the same way as the best approach we saw above. While 15.25 is still not too terrible (you execute the program before you go to bed, and its results will be available in the afternoon the next day.), it is worth parallelizing this process even taking into account for the time you need to spend to code the parallelization process.
6.1.3 Summary
- Do not let each core runs small tasks over and over again (extracting raster values for one polygon at a time), or you will suffer from significant overhead.
- Blocking is one way to avoid the problem above.
- Reduce the size of the outcome of each core as much as possible to spend less time to simply collating them into one.
- Do not forget about the time you would spend on coding parallelized processes.
6.2 Many multi-layer raster files
Here we discuss ways to parallelize the process of extracting values from many of multi-layer raster files.
6.2.1 Datasets
We will use the following datasets:
- raster: daily PRISM data 2010 through 2019 stacked by month
- polygons: US County polygons
daily PRISM precipitation 2010 through 2019
You can download all the prism files from here. For those who are interested in learning how to generate the series of daily PRISM data files stored by month, see section 9.3 for the code.
US counties
(
US_county <-
st_as_sf(maps::map(database = "county", plot = FALSE, fill = TRUE)) %>%
#--- get state name from ID ---#
mutate(state = str_split(ID, ",") %>% lapply(., `[[`, 1) %>% unlist()) %>%
#--- project to the CRS of the CDL data ---#
st_transform(projection(brick("Data/PRISM/PRISM_ppt_y1990_m12.tif")))
)Simple feature collection with 3076 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -124.6813 ymin: 25.12993 xmax: -67.00742 ymax: 49.38323
Geodetic CRS: +proj=longlat +datum=NAD83 +no_defs
First 10 features:
ID geom state
alabama,autauga alabama,autauga MULTIPOLYGON (((-86.50517 3... alabama
alabama,baldwin alabama,baldwin MULTIPOLYGON (((-87.93757 3... alabama
alabama,barbour alabama,barbour MULTIPOLYGON (((-85.42801 3... alabama
alabama,bibb alabama,bibb MULTIPOLYGON (((-87.02083 3... alabama
alabama,blount alabama,blount MULTIPOLYGON (((-86.9578 33... alabama
alabama,bullock alabama,bullock MULTIPOLYGON (((-85.66866 3... alabama
alabama,butler alabama,butler MULTIPOLYGON (((-86.8604 31... alabama
alabama,calhoun alabama,calhoun MULTIPOLYGON (((-85.74313 3... alabama
alabama,chambers alabama,chambers MULTIPOLYGON (((-85.59416 3... alabama
alabama,cherokee alabama,cherokee MULTIPOLYGON (((-85.46812 3... alabama6.2.2 Non-parallelized extraction
We have already learned in Chapter 5.3 that extracting values from stacked raster layers is faster than doing so from multiple single-layer raster datasets one at a time. Here, daily precipitation datasets are stacked by year-month and saved as multi-layer GeoTIFF files. For example, PRISM_ppt_y2009_m1.tif stores the daily precipitation data for January, 2009. This is how long it takes to extract values for US counties from a month’s of daily PRISM precipitation data.
tic()
temp <- exact_extract(stack("Data/PRISM/PRISM_ppt_y2009_m1.tif"), US_county, progress = F)
toc()elapsed
26.571 Now, to process all the precipitation data from 2009-2018, we consider two approaches in this section are:
- parallelize over polygons (blocked) and do regular loop over year-month
- parallelize over year-month
6.2.3 Approach 1: parallelize over polygons and do regular loop over year-month
For this approach, let’s measure the time spent on processing one year-month PRISM dataset and then guess how long it would take to process 120 year-month PRISM datasets.
#--- number of polygons in a group ---#
num_in_group <- floor(nrow(US_county) / num_cores)
#--- define group id ---#
US_county <- US_county %>%
mutate(
#--- create grid id ---#
poly_id = 1:nrow(.),
#--- assign group id ---#
group_id = poly_id %/% num_in_group + 1
)
extract_by_group <- function(i) {
temp_return <- exact_extract(
stack("Data/PRISM/PRISM_ppt_y2009_m1.tif"),
filter(US_county, group_id == i)
) %>%
#--- combine the list of data.frames into one with polygon id ---#
rbindlist(idcol = "id_within_group") %>%
#--- find the count of land use type values by polygon ---#
melt(id.var = c("id_within_group", "coverage_fraction")) %>%
.[, sum(value * coverage_fraction) / sum(coverage_fraction), by = .(id_within_group, variable)]
return(temp_return)
}
tic()
temp <- mclapply(1:num_cores, extract_by_group, mc.cores = num_cores)
toc()elapsed
83.694 Okay, so this approach does not really help. If we are to process 10 years of daily PRISM data, then it would take roughly 167.39 minutes.
6.2.4 Approach 2: parallelize over the temporal dimension (year-month)
Instead of parallelize over polygons, let’s parallelize over time (year-month). To do so, we first create a data.frame that has all the year-month combinations we will work on.
(
month_year_data <- expand.grid(month = 1:12, year = 2009:2018) %>%
data.table()
)The following function extract data from a single year-month case:
get_prism_by_month <- function(i, vector) {
temp_month <- month_year_data[i, month] # month to work on
temp_year <- month_year_data[i, year] # year to work on
#--- import raster data ---#
temp_raster <- stack(paste0("Data/PRISM/PRISM_ppt_y", temp_year, "_m", temp_month, ".tif"))
temp <- exact_extract(temp_raster, vector) %>%
#--- combine the extraction results into one data.frame ---#
rbindlist(idcol = "row_id") %>%
#--- wide to long ---#
melt(id.var = c("row_id", "coverage_fraction")) %>%
#--- find coverage-weighted average ---#
.[, sum(value * coverage_fraction) / sum(coverage_fraction), by = .(row_id, variable)]
return(temp)
gc()
}We then loop over the rows of month_year_data in parallel.
tic()
temp <- mclapply(1:nrow(month_year_data), function(x) get_prism_by_month(x, US_county), mc.cores = num_cores)
toc()elapsed
451.477 It took 7.52 minutes. So, Approach 2 is the clear winner.
6.2.5 Memory consideration
So far, we have paid no attention to the memory footprint of the parallelized processes. But, it is crucial when parallelizing many large datasets. Approaches 1 and 2 differ substantially in their memory footprints.
Approach 1 divides the polygons into a group of polygons and parallelizes over the groups when extracting raster values. Approach 2 extracts and holds raster values for 19 of the whole U.S. polygons. So, Approach 1 clearly has a lesser memory footprint. Approach 2 used about 40 Gb of the computer’s memory, almost maxing out the 64 Gb RAM memory of my computer (it’s not just R or C++ that are consuming RAM memory at the time). If you do not go over the limit, it is perfectly fine. Approach 2 is definitely a better option for me. However, if I had 32 Gb RAM memory, Approach 2 would have suffered a significant loss in its performance, while Approach 1 would not have. Or, if the raster data had twice as many cells with the same spatial extent, then Approach 2 would have suffered a significant loss in its performance, while Approach 1 would not have.
It is easy to come up with a case where Approach 1 is preferable. For example, suppose you have multiple 10-Gb raster layers and your computer has 16 Gb RAM memory. Then, Approach 2 clearly does not work, and Approach 1 is your only choice, which is better than not parallelizing at all.
In summary, while letting each core process a larger amount of data, you need to be careful not to exceed the RAM memory limit of your computer.