1 Reproducible Research
The objective of this chapter is to offer guidance on conducting research in a reproducible manner. It begins by defining reproducible research in Section 1.1, discusses the elements of high-quality reproducible research in Section 1.2, and concludes by highlighting the benefits associated with conducting research reproducibly in Section 1.3.
1.1 What is reproducible research
First of all, you may have heard of “reproducibility” and “replicability.” While they sometimes are used interchangeably, they mean different things. Here are commonly used definitions of the two terms (Cacioppo et al. 2015).
- Reproducibility: A research study is reproducible if anybody (including the author of the study) can generate exactly the same results by using the same materials (e.g., data) and procedures used in the study.
- Replicability: A research study is replicable if other teams reach the same conclusion by applying the same procedure to the different materials (e.g., data).
This book focuses only on reproducibility and do not deal with replicability.
What makes a research project reproducible?
Note that this does not necessarily mean every single action needs to be computer-programmed and automated. Even if you manually delete rows of data on Excel (highly discouraged), this does not make your research non-reproducible as long as this action is recorded and the original data (before deletion of the rows) are provided because anybody can implement this action. Many economists use STATA as their primary software and it provides GUI for creating a figure like below.
Using a GUI like this does not inherently render your research non-reproducible. Provided you give a clear guideline on how to utilize the GUI (along with the dataset), your research remains replicable
It is crucial to distinguish between the quality of data and methodology and the concept of reproducibility. Let’s say a research team omits certain observations they should not have or neglects to include vital independent variables in their regression analysis. Although such oversights might compromise the reliability of their findings, they do not render the research non-reproducible. So long as those steps are documented and the data is accessible, the research can be reproduced. At its core, reproducibility is all about transparency. While ensuring reproducibility often improves the quality of results, it is important to understand that low-quality outcomes do not equate to non-reproducibility.
1.2 High-quality reproducible research
A high-quality reproducible project exhibits the following characteristics:
Organized Project Folder: It maintains a well-structured and organized project folder, making it easy to locate the necessary files.
Streamlined Automation: Workflows are automated with well-annotated computer programs, simplifying the replication process and providing clarity in the workflow.
Comprehensive Documentation: Robust documentation, encompassing data and reproduction guidance, ensures transparency, saving time on data interpretation and replication instructions.
1.2.1 Organized project folder
A well-organized project folder can substantially decrease the cost of updating and reproducing the project, primarily due to the ease of locating files. This is particularly true for those outsider the author team. When you are new to research, figuring out how to structure an organized project folder can be daunting. I recall my early days as an MS student when all sorts of files were jumbled together in a single folder, lacking any organizational structure. Datasets, code, results, figures, journal articles—everything was mixed. This haphazard arrangement made finding the right file an arduous task, significantly increasing the cost and effort required for reproduction, not only for others but also for myself and my team. A structured approach to constructing an organized project folder is detailed in Chapter 2.
1.2.2 Streamlined Automation
Automation
As stated above as examples, removing rows of data in Excel or producing a figure using a GUI does not inherently render a research project non-reproducible. However, such practices are not reproduction-friendly as they elevate the time required for reproduction possibly to the point where reproduction is not reasonably feasible. Automation of such procedures can significantly reduce the cost of repeating the same procedures for other members of your team or those who are tying to reproduce the results.
Where automation is possible depends on the nature of the data and analysis used in the analysis. If it is a simulation analysis where data is generated by a computer program, then it is possible to automate every single step of the research. This is a fully automated reproducible research. Even if you use real-world data, it can be a fully automated research. This is when all the datasets used in the research is publicly available and downloadable through computer programs. For example, you can use PRISM weather dataset (downloadable using the prism package) and county-level corn yield data (downloadable using the tidyusda package) to estimate the impact of temperature and precipitation on corn yield. This research can be made fully reproducible from the very beginning to the end. Many research projects cannot be made fully automated because datasets are often not downloadable using a computer program even if they are publicly accessible online. If you are using data you have collected using paper surveys, then it is simply impossible to automate this process because manual entry of data is necessary.
One thing that is common for all these types of projects is that you can automate everything given the raw data files are stored (no matter how they are obtained). Indeed, this is the focus of this book. Starting from the next chapter, how to develop an automated reproducible project is discussed given the raw data is available and sharable.
When non-sharable confidential data is used, reproducibility of the project is severely compromised. However, all the codes should be made accessible at least. Sometimes coding error can be detected even without running them.
Streamlining
Suppose the computer programs for reproducing results contain exploratory and experimental codes that were used during experimentation, and the crucial parts of the code responsible for generating the main results are unclear and somewhat concealed. In such cases, the programs lack streamlining, generating extraneous information that can distract those attempting to reproduce the research.
Streamlined computer programs typically exhibit following characteristics:
- The entire process is divided into smaller components based on their roles, such as data processing, analysis, and generating tables and figures.
- The sequence in which the code segments are executed is immediately evident to anyone.
- The inputs and outputs for each of these processes are clearly defined, and it’s easy to identify the dependencies between objects and code segments.
For example, consider a relatively simple project that consists of four main R code files.
- process_data.R
- analyze_data.R
- make_figures_tables.R
- render_manuscript.R
Here is the input/output relationship of these files.

You can then have a master code file that runs all the codes to complete entire process that looks like the following:
source("process_data.R")
source("analyze_data.R")
source("make_figures_tables.R")
source("render_manuscript.R")Well-organized and well-annotated code
Each of the computer program files should be well structured/organized inside and well-annotated.
Here is an example of well-organized and well-annotated R code file.
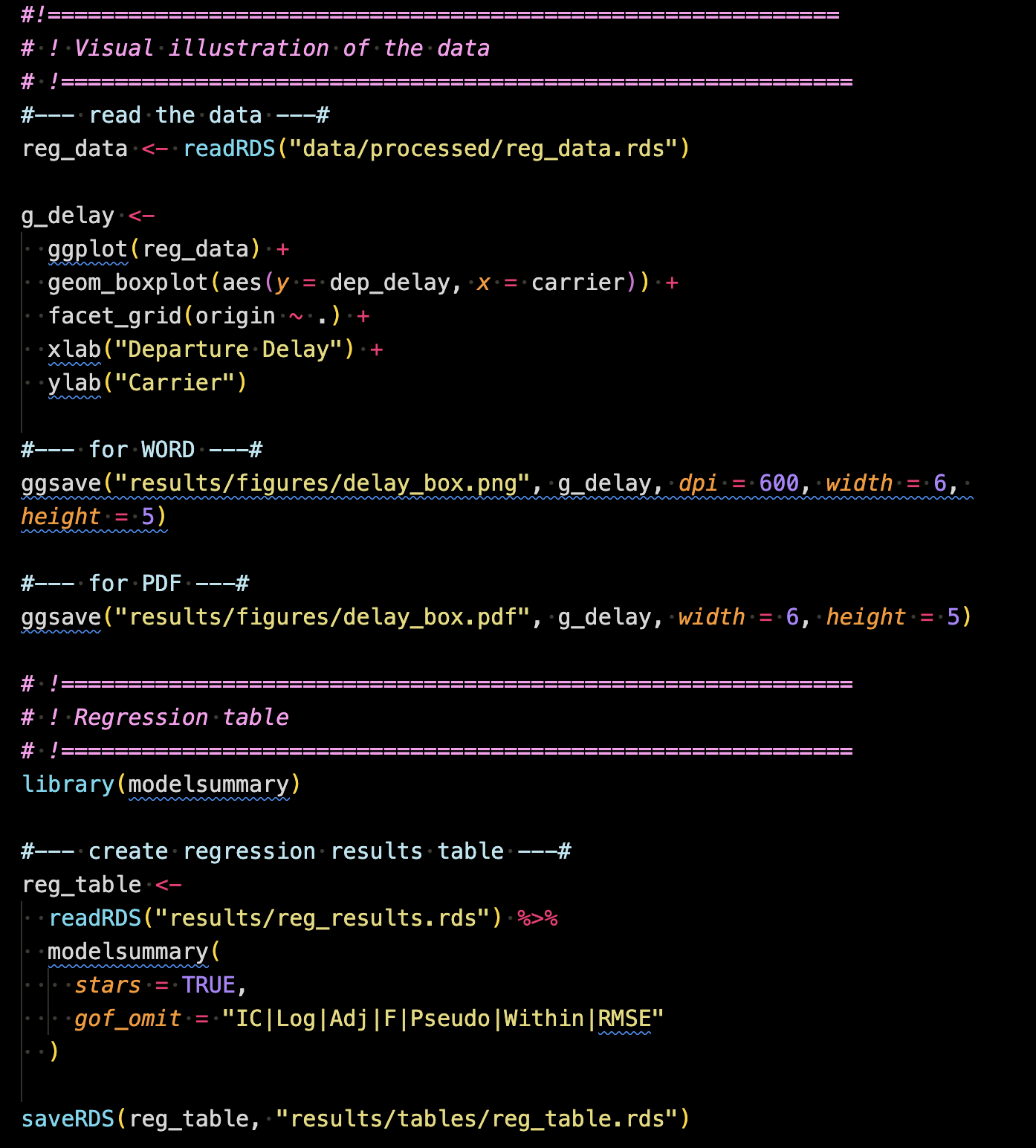
This R script is designed to generate a single figure and table. It is compartmentalized into two distinct sections within the file, each clearly labeled for its purpose. The first section is dedicated to “Visual illustration of the data,” while the second section focuses on generating a “Regression table.” These clear headings make it evident which part of the code serves what purpose. Additionally, you can find informative notes within each compartment, providing further context and clarifying the intent behind specific code chunks. While this example represents a straightforward R code file, it effectively illustrates the concept of organizing code for clarity and comprehension.
1.2.3 Comprehensive documentation
Comprehensive documentation of data is paramount. Any meaningful updates or attempts at reproducing results must begin with a clear understanding of the data. To achieve this, it is imperative to provide documentation regarding the data sources and the definition of each variable (metadata). This step helps minimize the cost of understanding the data for both you and others involved in the research.
When the entire research process is automated through well-annotated code, the code itself becomes an excellent form of documentation, capturing the procedures undertaken in the study. In such cases, providing a guideline on how to run the code can be beneficial and sufficient. However, if certain procedures are conducted manually, they should be meticulously documented to ensure that anyone can follow them with precision.
1.3 Why high-quality reproducible research?
The main beneficiaries of reproducible research include:
- You (Y)
- Members of your team (M)
- The scientific community (S)
Indeed, reproducible research does not just benefit other scientists; it serves as an valuable aid to yourself, your future self, and your team members. Let’s delve into some of the key advantages linked to high-quality reproducible research.
By adhering to recommended practices for high-quality reproducible research, you and your team can benefit not only after but also during the ongoing research project. The benefits accrued during the project’s completion often outweigh those realized after the project concludes.
Some of the benefits are listed below. Letters in the parenthesis right to the title indicate the abbreviation of the major beneficiaries listed above.
Scientific Integrity and Error Prevention (S)
Reproducible research offers the scientific community an opportunity to reevaluate a project and assess the reliability of its results. As a result, any errors made by the authors can be identified and corrected, potentially leading to different conclusions. This corrective process can, for instance, prevent the implementation of misguided policies and spare subsequent research endeavors from being built upon erroneous conclusions, ultimately saving researchers’ time and resources.
Educational Value (MS)
High-quality reproducible research serves as a valuable educational tool, especially for students new to a field. It offers numerous insights that can be gleaned from the process of reproducing such a project. In fact, I routinely encourage my students to meticulously go through one of the reproducible projects completed by my team, dissecting it line by line. This hands-on experience provides students with a practical opportunity to grasp essential aspects of reproducible research, such as streamlined automation, comprehensive documentation, and well-annotated, organized code. Moreover, they can familiarize themselves with the coding style employed by the team.
Repeatability (YM)
During a research project, you are likely to repeat certain procedures multiple (sometimes many) times. For instance, upon receiving new observations, you might need to reanalyze the data. If you processed and analyzed data manually using a GUI and did not save the codes, you would have to restart the entire process. In contrast, if you have coded all procedures, rerunning them is straightforward.
Scientific findings are often conveyed in tables and figures, which are frequently updated throughout research. You might, for example, identify outliers and exclude them from your analysis, necessitating changes in regression results tables. Similarly, reviewers could suggest model adjustments, prompting further updates. Crafting tables and figures manually means redoing them each time changes arise.
Transferability (YM)
One of the key advantages of reproducible research is the seamless (or less costly) transition of project ownership. With streamlined automation with well-annotated codes and complete documentation, it is much easier to hand over the leadership of the project to another individual, whether for the continuation of the current project or as the foundation for a new project that builds upon it.
Imagine you are serving as the academic advisor to a Master’s student who, before completing the refinement of their thesis results for journal publication, transitions to a different institute, such as a Ph.D. program at a different university or a private company. In this situation, you’ve made the decision to assign the task to another student. However, if the research procedures were not well-documented, the new student may find themselves investing a substantial amount of time in understanding and processing the data before being able to conduct more advanced analyses.
At times, you may find yourself returning to a research project after several years, armed with new research ideas and additional observations for the same dataset. When the data is well-documented, and data processing was automated, you can seamlessly initiate new analyses without investing time in redundant data processing. However, if data processing was initially done manually in tools like Excel, you may face the need to redo these tasks, which can prove highly time-consuming.
Reducing Errors (YM)
Computer-automated research has the power to significantly reduce errors commonly associated with manual processes. Consider, for instance, the task of referencing a specific statistic from a regression results table within your discussion. When results change, it is not hard to overlook updating that particular statistic in your narrative. However, with the ability to programmatically reference this statistic directly from the table within the document, achieved through tools like R Markdown and QMD, any alterations to the results will automatically update the corresponding reference in your discussion. This automation effectively eliminates the risk of manual oversight.