R as GIS: Interaction of Vector and Raster Datasets
Extract values from raster layers to a vector data
Definition
For each of the points, find which raster cell it is located within, and assign the value of the cell to the point.
Example
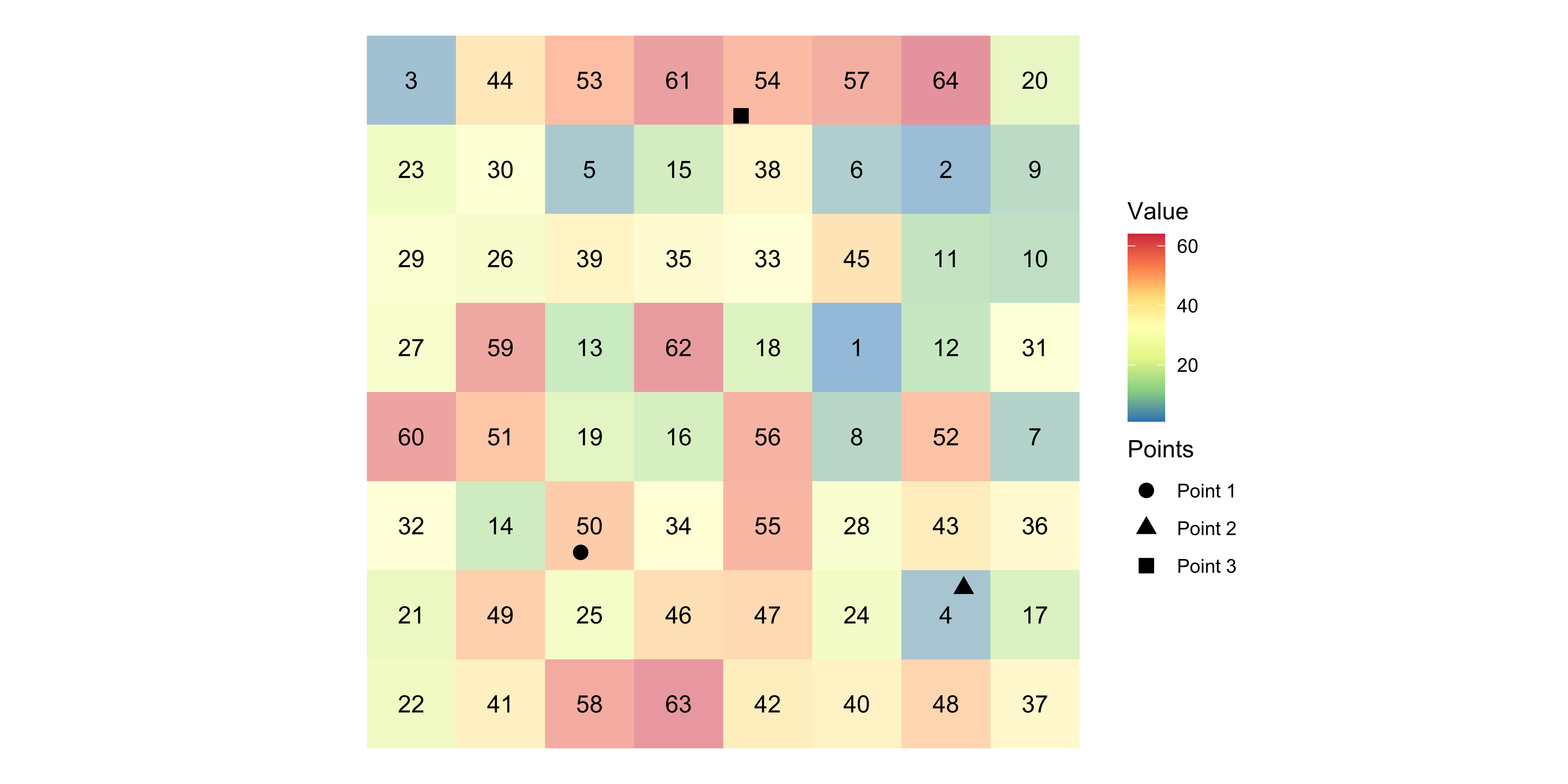
The numbers inside the cells are the values that the cells hold.
After the extraction,
- Point 1 will be assigned \(50\)
- Point 2 will be assigned \(4\)
- Point 3 will be assigned \(54\).
Definition
For each of the polygons, identify all the raster cells that intersect with the polygon, and assign a vector of the cell values to the polygon.
Example
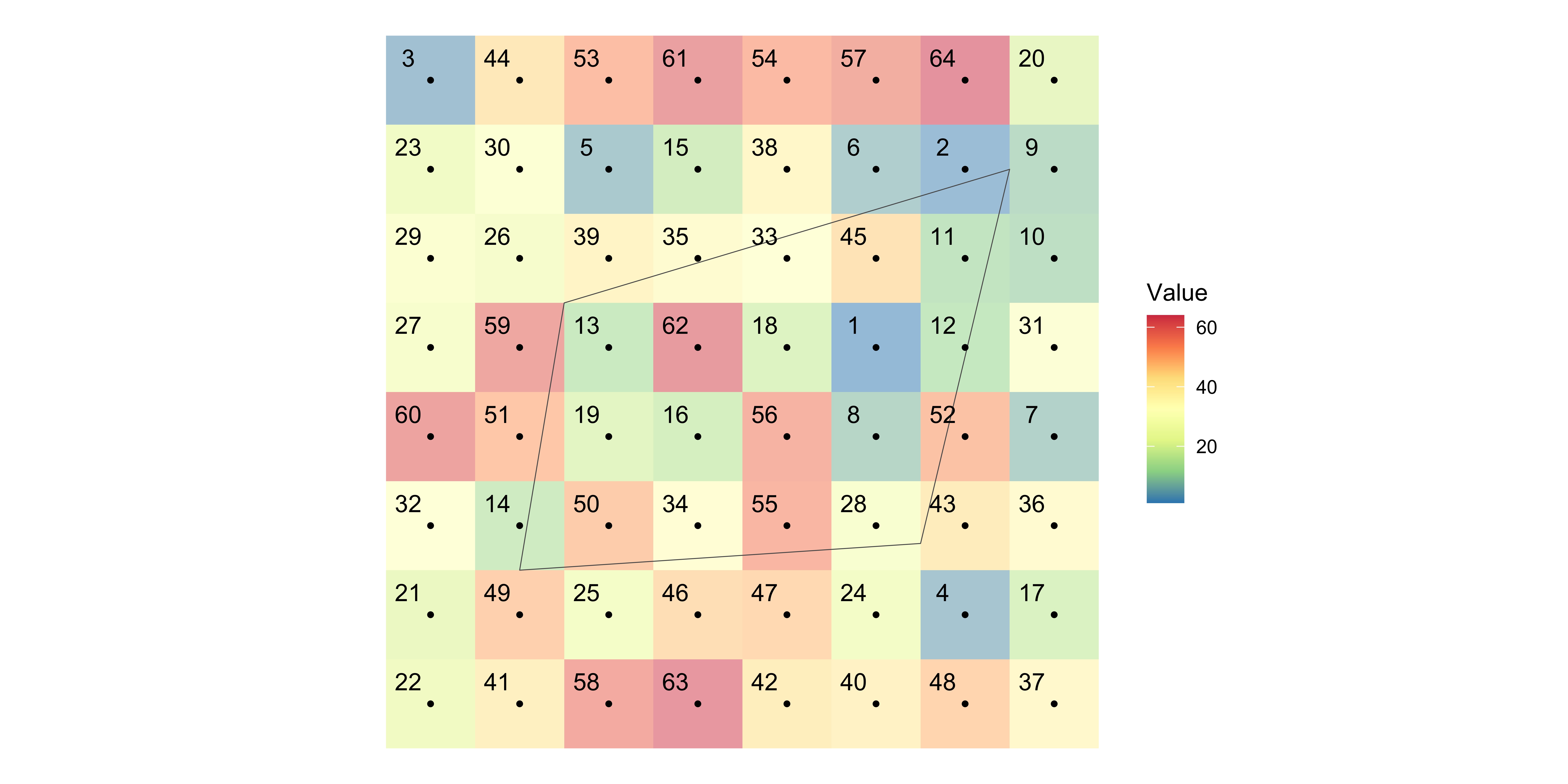
Find all the raster cells each of the polygons “intersect with”
Assign the value of all the intersecting cells to the polygon (n-to-1).
Right now, corn yields (
corn_yield), NDRE (NDRE), and treatment blocks (treatment_blocks) are separate R objects.We would like to conduct two kinds of analysis
- analysis based on data where yield points are the unit of observations
- analysis based on data where treatment blocks are the unit of observations
To achieve this, we would like to
jointhem based on their locations- extract values from ‘NDRE’ to
corn_yield - extract values from ‘NDRE’ to
treatment_blocks
- extract values from ‘NDRE’ to
You can use terra::extract() with the following syntax.
Syntax
Extract NDRE values to each of the yield points:
Oops, we did it again.
Just extracting the raster values to the points is not where we stop.
We need to merge the extracted values back to the points data so that we can use them for further analysis.
Let’s first check the class of NDRE_extracted.
The nth row in NDRE_extracted is for the nth point in yield.
So, you can simply do this:
You can extract values from multiple layers at the same time using terra::extract() just like you did with a single-layer raster data.
For demonstration, let’s create a multi-layer raster data:
The resulting object is a data.frame and the values from first (second) layer is the second (third) column.
- How
- Demonstration
- Post-extraction processing
- Extract and summarize
- Area-weighted summarization
- Multiple layers
You can use terra::extract() with the following syntax. Yes, same as value extraction to points.
Syntax
Extract NDRE values to each of the treatment blocks:
It’s a data.frame.
As you can see below, there are more than one NDRE values for each of the treatment blocks, which is expected as there are many grid cells that are inside of them.
Let’s check the class of NDRE_extracted_tb.
We just want to one NDRE value for each of the treatment blocks. So, let’s summarize them. In doing so, we summarize by ID as it indicates the row number of treatment_blocks. Here, we are getting the average.
Now, we can assign the average NDRE values to treatment_blocks like below because ID == n is for nth row of treatment_blocks.
You can actually extract and summarize both in terra::extract() using the fun option.
In the previous cases of extraction and summarization tasks, all the intersecting cells are given the same weight irrespective of the degree of spatial overlap.
This is very much acceptable in the current application, because the resolution of the raster data is high (cells are so small) relative to the size of the polygons.
However, if the cells are relatively large, you might want to consider calculating area-weighted summary.
We can add exact = TRUE option, which returns fraction variable indicating the fraction of the cells intersecting with the polygon.
Just like the case with value extraction to points, we can extract values from multiple layers to polygons in a single call with terra::extract().
Let’s get the weighted average for both variables: