09-6: R as GIS: Download Spatial Datasets using R
U.S. county and state boundary
U.S. county and state boundary data are commonly used in many scientific studies.
The
tigrispackage is one of the packages that let you download them from within R.It lets you download much more than just county and state boundaries. See other type of data here
You can use
tigris::states()to download the state boundary data as ansfobject.By default, the most detailed boundary data is downloaded, which can be quite large
- creating map using
ggplot()can take significantly more time - the map can be quite large in size
- creating map using
By adding
cb = TRUE, you will get generalized (less detailed) boundary data, which is usually sufficient.
You can use
tigris::counties()to download the county boundary data as ansfobject.You can specify states by the
stateoption.
PRISM
PRISM dataset provide model-based estimates of daily precipitation, maximum temperature, and minimum temperature for the U.S. at the 4km by 4km spatial resolution.
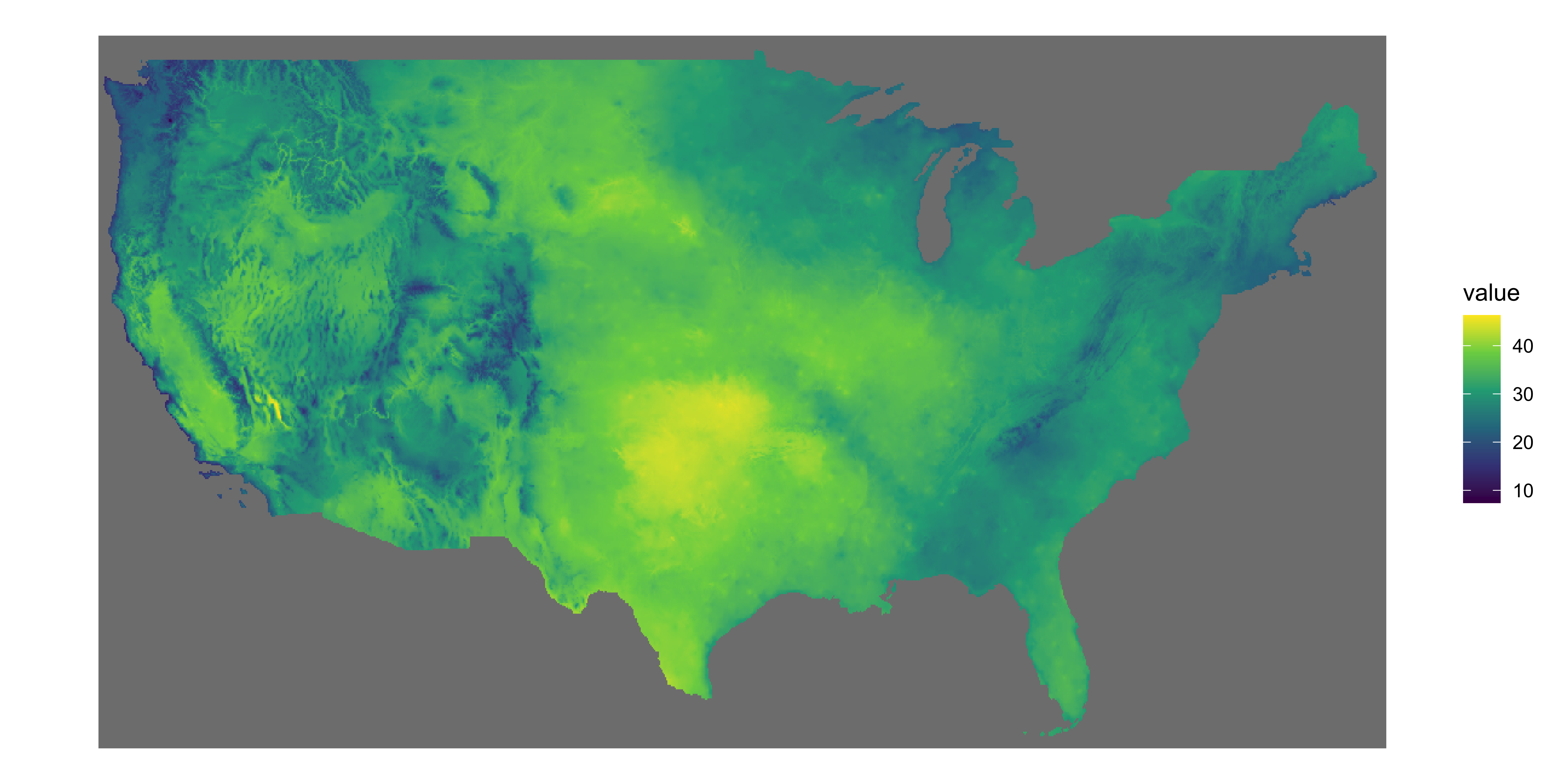
You can use get_prism_dailys() from the prism package to download PRISM data.
Syntax
type: you can select from “ppt” (precipitation), “tmean” (mean temperature), “tmin” (minimum temperature), and “tmax” (maximum temperature).minDate: starting date specified in format YYYY-MM-DDmaxDate: end date specified in format YYYY-MM-DDkeepZip: ifFALSE, the zipped folders of the downloaded files will not be kept; otherwise, they will be kept.
Before you download PRISM data using the function, it is recommended that you set the path to folder in which the downloaded PRISM files will be stored using.
First set the path:
Now, download:
This will create a single folder for each day of the specified date range. Inside of the folders, you will see bunch of files with the same name except extensions.
As you have seen, we would have many files to open unless the specified date range is very short. In such case, you should take advantage of a simple for loop.
First, the following code gives you the name of all the PRISM files with .bill extension.
(
prism_files_list <-
list.files("Data/PRISM", recursive = TRUE, full.names = TRUE) %>%
.[grep("\\.bil", .)] %>%
.[!grepl("aux", .)]
)[1] "Data/PRISM/PRISM_ppt_provisional_4kmD2_20240101_bil/PRISM_ppt_provisional_4kmD2_20240101_bil.bil"
[2] "Data/PRISM/PRISM_ppt_provisional_4kmD2_20240102_bil/PRISM_ppt_provisional_4kmD2_20240102_bil.bil"
[3] "Data/PRISM/PRISM_ppt_provisional_4kmD2_20240103_bil/PRISM_ppt_provisional_4kmD2_20240103_bil.bil"
[4] "Data/PRISM/PRISM_ppt_provisional_4kmD2_20240104_bil/PRISM_ppt_provisional_4kmD2_20240104_bil.bil"
[5] "Data/PRISM/PRISM_ppt_provisional_4kmD2_20240105_bil/PRISM_ppt_provisional_4kmD2_20240105_bil.bil"
[6] "Data/PRISM/PRISM_tmax_stable_4kmD2_20120801_bil/PRISM_tmax_stable_4kmD2_20120801_bil.bil"
[7] "Data/PRISM/tmax/PRISM_tmax_stable_4kmD2_20230601_bil/PRISM_tmax_stable_4kmD2_20230601_bil.bil"
[8] "Data/PRISM/tmax/PRISM_tmax_stable_4kmD2_20230602_bil/PRISM_tmax_stable_4kmD2_20230602_bil.bil"
[9] "Data/PRISM/tmax/PRISM_tmax_stable_4kmD2_20230603_bil/PRISM_tmax_stable_4kmD2_20230603_bil.bil" Just replace "Data/PRISM" with your folder path to the PRISM files.
We can now read them using terra::rast() like below:
class : SpatRaster
dimensions : 621, 1405, 9 (nrow, ncol, nlyr)
resolution : 0.04166667, 0.04166667 (x, y)
extent : -125.0208, -66.47917, 24.0625, 49.9375 (xmin, xmax, ymin, ymax)
coord. ref. : lon/lat NAD83
sources : PRISM_ppt_provisional_4kmD2_20240101_bil.bil
PRISM_ppt_provisional_4kmD2_20240102_bil.bil
PRISM_ppt_provisional_4kmD2_20240103_bil.bil
... and 6 more sources
names : PRISM~1_bil, PRISM~2_bil, PRISM~3_bil, PRISM~4_bil, PRISM~5_bil, PRISM~1_bil, ...
min values : 0.000, 0.0000, 0.0000, 0.0000, 0.0000, 7.408, ...
max values : 42.917, 10.2093, 87.7497, 37.0813, 90.0984, 46.303, ... Download PRISM maximum temperature data from “06-01-2023” to “06-03-2023”.
Answer
Read all the maximum temperature data files you just downloaded using terra::rast().
Answer
Crop Data Layer
The Cropland Data Layer (CDL) is a data product produced by the National Agricultural Statistics Service of U.S. Department of Agriculture.
CDL provides geo-referenced, high accuracy, 30 (after 2007) or 56 (in 2006 and 2007) meter resolution, crop-specific cropland land cover information for up to 48 contiguous states in the U.S. from 1997 to the present.
This data product has been extensively used in agricultural research. CropScape is an interactive Web CDL exploring system, and it was developed to query, visualize, disseminate, and analyze CDL data geospatially through standard geospatial web services in a publicly accessible on-line environment (Han et al., 2012).
This section shows how to use the CropScapeR package (Chen 2020) to download and explore the CDL data.
The package implements some of the most useful geospatial processing services provided by the CropScape, and it allows users to efficiently process the CDL data within the R environment.
Specifically, the CropScapeR package provides four functions that implement different kinds of geospatial processing services provided by the CropScape.
GetCDLData()in particular is the most important function as it lets you download the raw CDL data.The other functions provide the users with the CDL data summarized or transformed in particular manners that may suit the need of some users.
GetCDLData() allows us to obtain CDL data for any Area of Interest (AOI) in a given year. It requires three parameters to make a valid data request:
aoi: Area of Interest (AOI).year: Year of the data to request.type: Type of AOI.
The following AOI-type combinations are accepted:
- any spatial object as an sf or sfc object -
type = "b" - county (defined by a 5-digit county FIPS code) -
type = "f" - state (defined by a 2-digit state FIPS code) -
type = "f" - bounding box (defined by four corner points) -
type = "b" - polygon area (defined by at least three coordinates) -
type = "ps" - single point (defined by a coordinate) -
type = "p"
Suppose you are interested in getting CDL data for the entire Nebraska.
In this case we can use the state FIP code for NE (31) for
aoiand specifytypeto be"f"(Note that this would take some time if you run it.).This can take a while. Since the spatial resolution is 30m, the CDL data covering the entire IL would have lots of cells and thus memory-intensive.
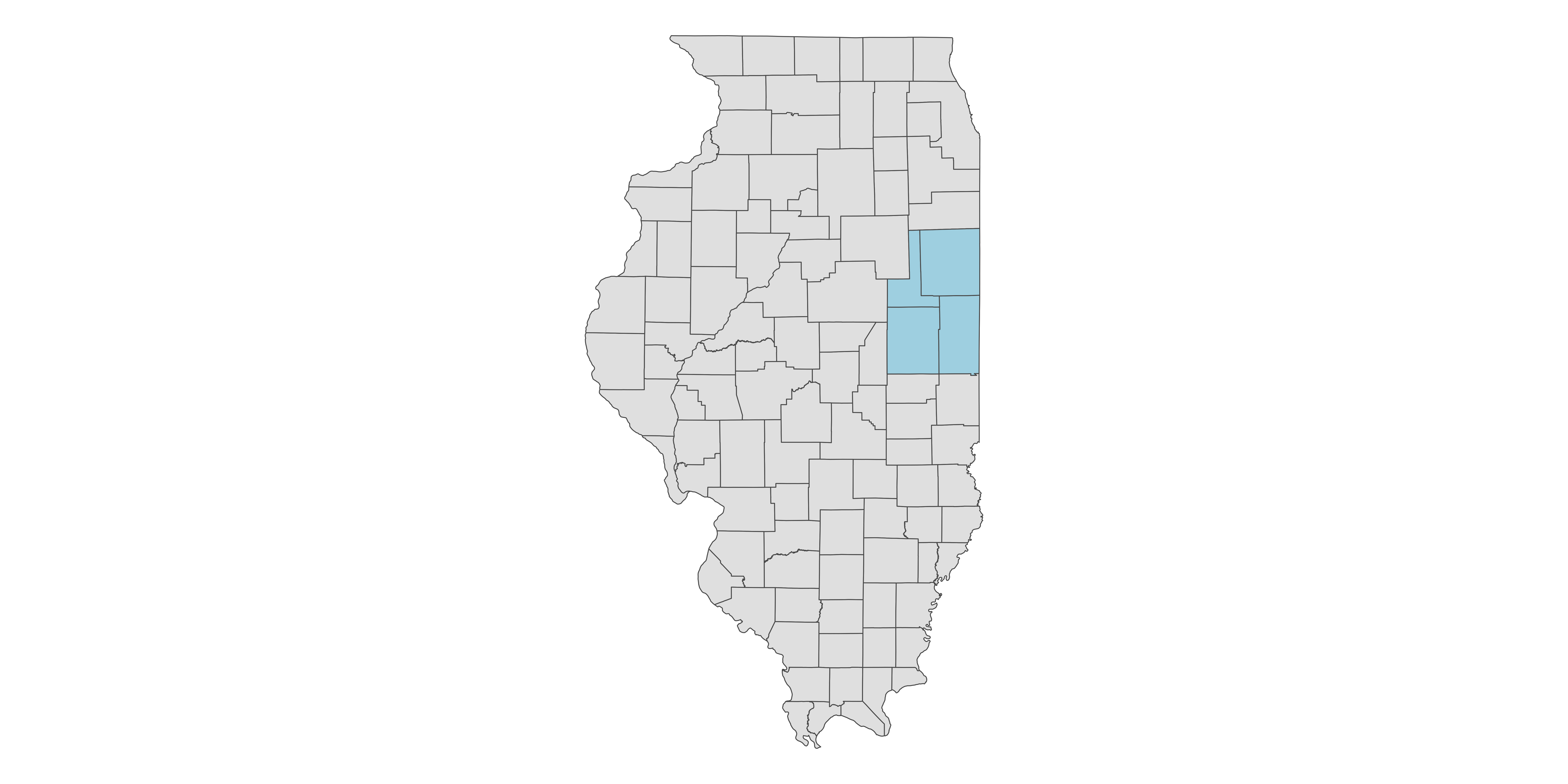
In this example, we are interested in obtaining CDL data for the following four counties in Illinois: Champaign, Vermilion, Ford, and Iroquois.
Let’s first get the county boundary data for them:
Here is where they are:
Using the tigris package, download the county boundary for Iowa, and then filter it to keep only the Sioux county. Name the sf file sioux_county.
Answer
Using the CropScapeR::GetCDLData(), download the 2022 CDL data covering the Sioux County. Then, convert it to a SpatRaster object. Name the final product sioux_cdl_2022.
Answer
Mask the CDL data you just downloaded using sioux_county using terra::mask().
Answer
Before creating a map from the downloaded CDL layer data, let’s aggregate the data by factor of 10 using terra::aggregate(). Call it sioux_aggregated.
Answer