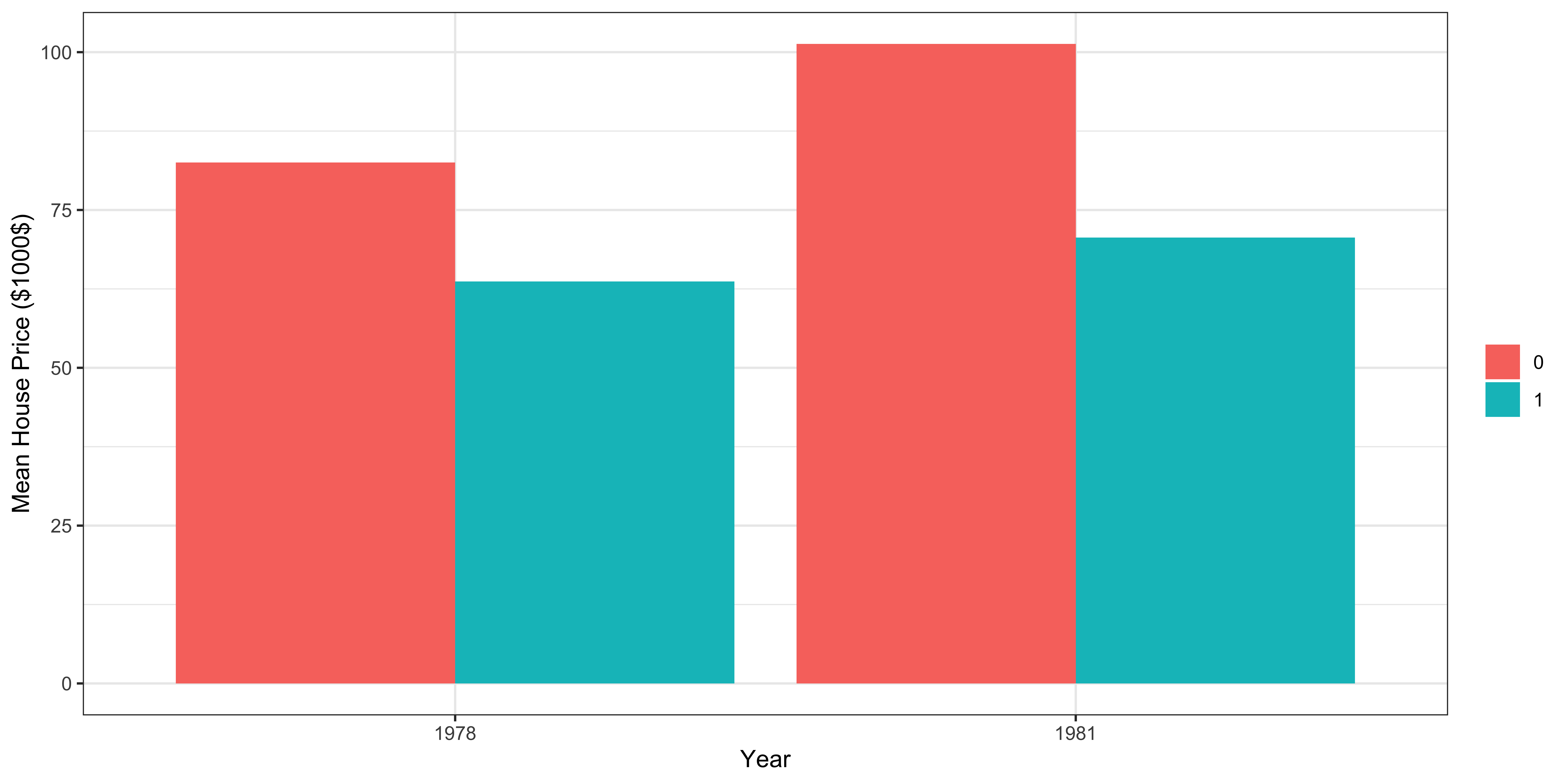
12: Difference in Differences (DID)
DID implementation using R
Well-level groundwater use data in Kansas
site year af_used in_LEMA pr et0 awc bulkdensity
<int> <num> <num> <num> <num> <num> <num> <num>
1: 160 1991 195.328540 1 401.9 1047.3311 0.1859333 1.359156
2: 160 1992 62.390479 1 463.9 904.0815 0.1859333 1.359156
3: 160 1993 40.214699 1 615.6 842.7572 0.1859333 1.359156
4: 160 1994 155.113840 1 405.5 1028.4635 0.1859333 1.359156
5: 160 1995 103.093132 1 488.5 890.5116 0.1859333 1.359156
---
34121: 82261 2019 5.277566 0 598.4 961.0884 0.2078054 1.383747
34122: 82288 2018 0.007672 0 425.7 1069.7815 0.1823573 1.269078
34123: 82538 2017 195.000000 0 563.2 1027.4662 0.2063358 1.287400
34124: 82538 2018 158.000000 0 554.7 1092.2203 0.2063358 1.287400
34125: 82538 2019 136.000000 0 544.8 1011.2639 0.2063358 1.287400Main variables
site: wellaf_used: groundwater used (dependent variable)in_LEMA: whether located inside the LEMA region or notyear: year
Control and Treatment Units
- (to be) treated: wells inside the red boundary (LEMA)
- control: wells outside the red boundary (LEMA)
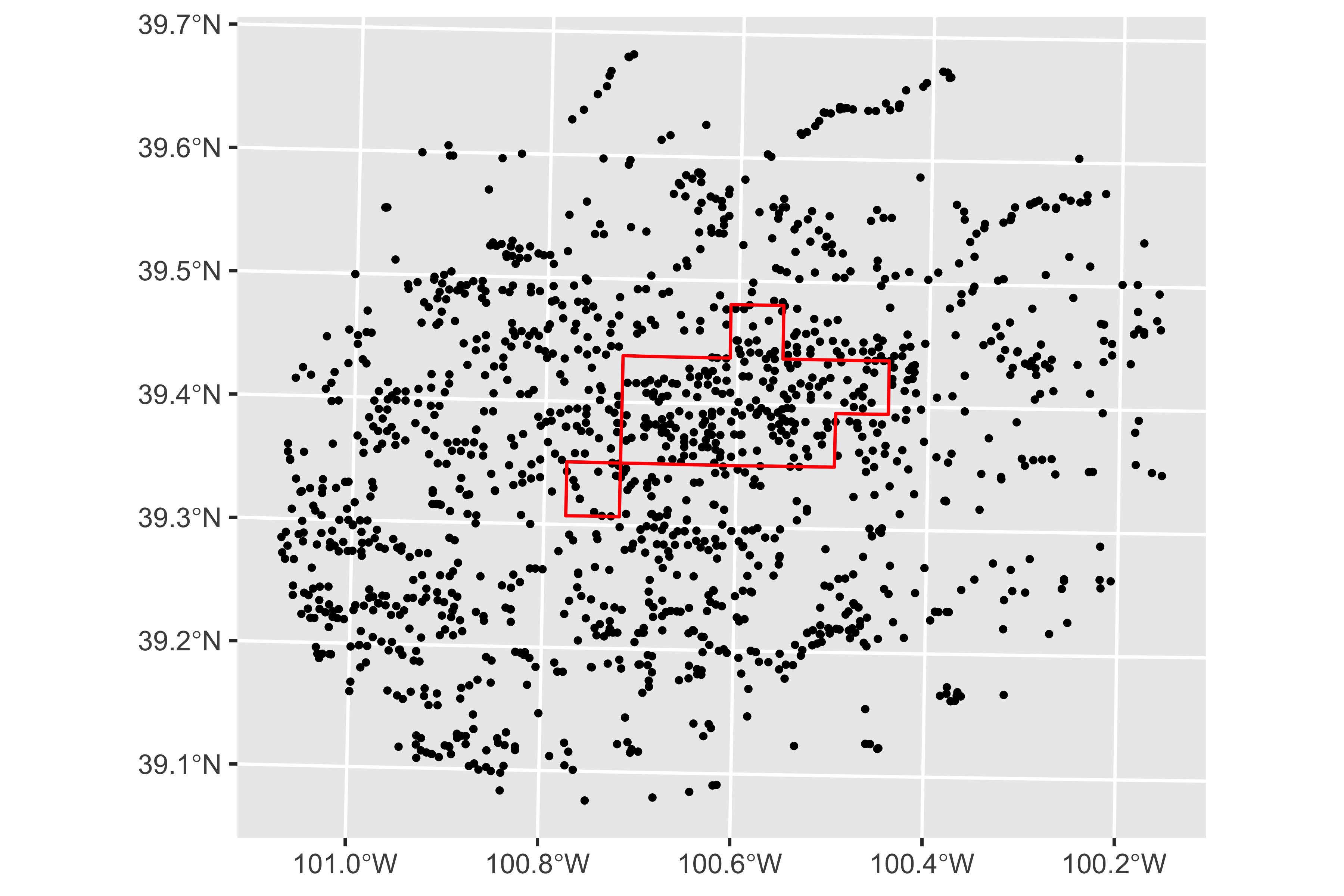
Before and After
Effective 2013, wells located inside the LEMA can pump groundwater up to a certian amount
- before: ~ 2012
- after: 2013 ~
Data transformation:
before or after
Take a look at the one of the wells:
site year before_after
<int> <num> <num>
1: 160 2001 0
2: 160 2002 0
3: 160 2003 0
4: 160 2004 0
5: 160 2005 0
6: 160 2006 0
7: 160 2007 0
8: 160 2008 0
9: 160 2009 0
10: 160 2010 0
11: 160 2011 0
12: 160 2012 0
13: 160 2013 1
14: 160 2014 1
15: 160 2015 1
16: 160 2016 1
17: 160 2017 1
18: 160 2019 1(to be) treated or not
Whether wells are (to be) treated or not is already there in this dataset, represented by in_LEMA
DID estimating equation (in general)
\[ \begin{aligned} y_{i,t} = \alpha_0 + \beta_1 before\_after_t + \beta_2 treated\_or\_not_i + \beta_3 before\_after_t \times treated\_or\_not_i + X_{i,t}\gamma + v_{i,t} \end{aligned} \]
The variable of interest is \(\beta_3\), which measures the impact of the treatment.
R code
fixest::feols(
af_used ~ before_after + in_LEMA + I(before_after * in_LEMA) + pr + et0,
cluster = ~site,
data = lema_data
)OLS estimation, Dep. Var.: af_used
Observations: 34,125
Standard-errors: Clustered (site)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 185.829056 7.153231 25.97834 < 2.2e-16 ***
before_after -9.034901 1.034500 -8.73359 < 2.2e-16 ***
in_LEMA 30.001586 3.224780 9.30345 < 2.2e-16 ***
I(before_after * in_LEMA) -34.762264 2.097251 -16.57516 < 2.2e-16 ***
pr -0.187841 0.005100 -36.83260 < 2.2e-16 ***
et0 0.013708 0.005033 2.72326 0.0065454 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 71.4 Adj. R2: 0.10752DID does NOT require panel data. Two periods of cross-setional data are sufficient. But, if you have panel data, you can certainly include individual fixed effects, which would certainly help to control for time-invariant characteristics (both observed and unobserved)
fixest::feols(
af_used ~ before_after + in_LEMA + I(before_after * in_LEMA) + pr + et0 | site,
cluster = ~site,
data = lema_data
)OLS estimation, Dep. Var.: af_used
Observations: 34,125
Fixed-effects: site: 1,383
Standard-errors: Clustered (site)
Estimate Std. Error t value Pr(>|t|)
before_after -8.748317 0.837889 -10.44090 < 2.2e-16 ***
I(before_after * in_LEMA) -36.550589 1.961441 -18.63456 < 2.2e-16 ***
pr -0.185034 0.004263 -43.40657 < 2.2e-16 ***
et0 0.019343 0.003955 4.89076 1.1221e-06 ***
... 1 variable was removed because of collinearity (in_LEMA)
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 43.6 Adj. R2: 0.652695
Within R2: 0.226595Notice that in_LEMA was dropped due to perfect collinearity (this is not a problem). in_LEMA is effectively controlled for by including individual fixed effects.
If you have multiple years of observations in the before and after periods, you can (and should) include year fixed effects.
fixest::feols(
af_used ~ before_after + in_LEMA + I(before_after * in_LEMA) + pr + et0 | site + year,
cluster = ~site,
data = lema_data
)OLS estimation, Dep. Var.: af_used
Observations: 34,125
Fixed-effects: site: 1,383, year: 29
Standard-errors: Clustered (site)
Estimate Std. Error t value Pr(>|t|)
I(before_after * in_LEMA) -37.149761 1.961915 -18.93546 < 2.2e-16 ***
pr -0.114725 0.007728 -14.84493 < 2.2e-16 ***
et0 0.052997 0.030668 1.72807 0.084198 .
... 2 variables were removed because of collinearity (before_after and in_LEMA)
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 40.7 Adj. R2: 0.698229
Within R2: 0.025545Notice that before_after was dropped due to perfect collinearity (this is not a problem). before_after is effectively controlled for by including year fixed effects. Indeed, year fixed effects provide a tighter controls on annual macro shocks.
How to argue your DID is reliable
Important
Selecting the right control group is important in DID. If the following conditions are satisfied, it is more plausible that the control and treatment groups would have had the same macro shock \((\alpha_1 = \alpha_0)\) if it were not for the treatment.
- There were no events that could significantly affect the dependent variable of the control group between the “before” and “after” period
- The two groups are generally similar so other factors do not drive the differences between them
- They had similar trajectories of the dependent variable prior to the treatment (possible if you have more than one years of data prior to the treatment)
- this does NOT guarantee that the their trends after the treatment are similar
To do
- Show the trajectory of the dependent variable
- Run placebo tests
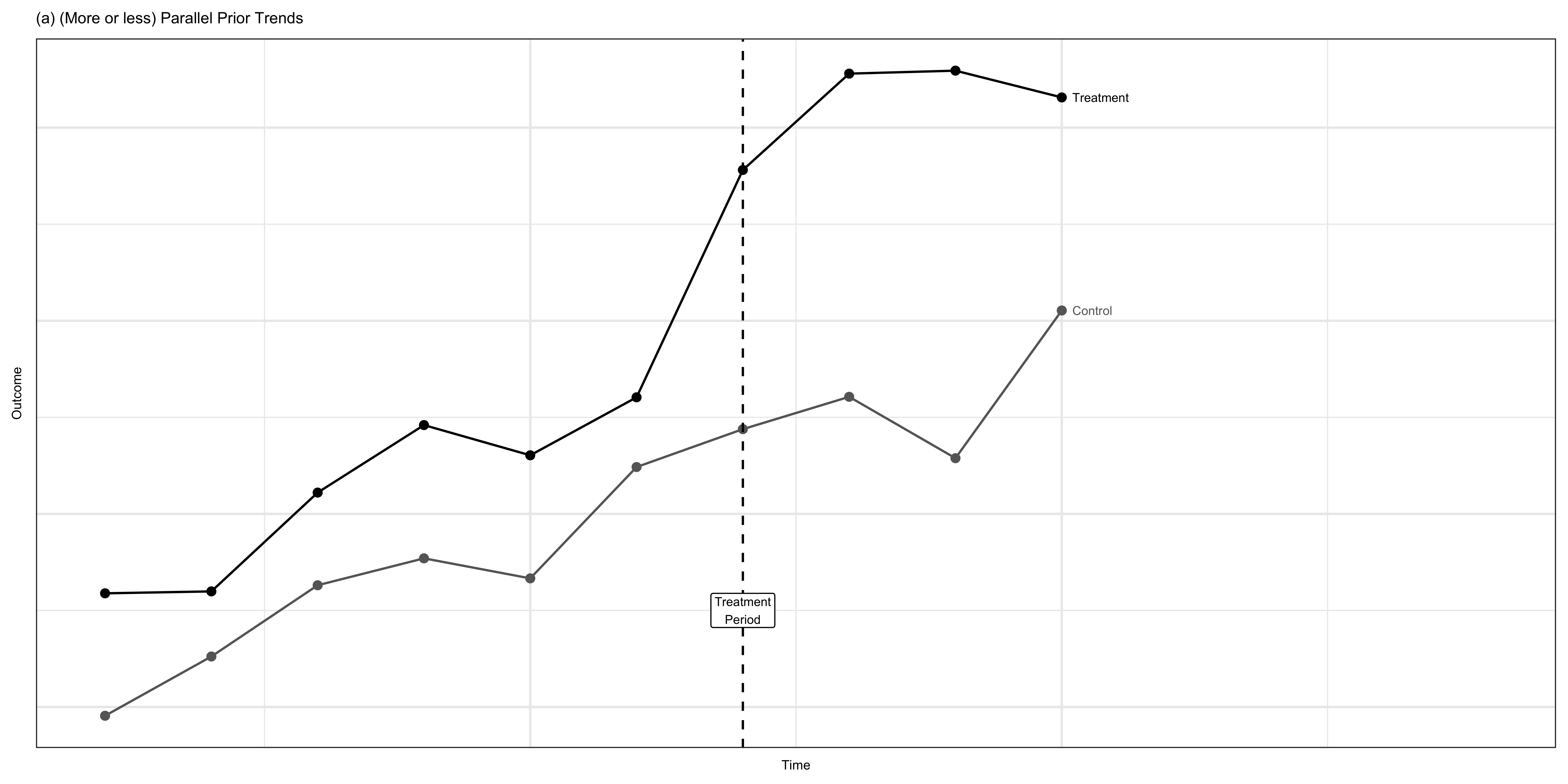
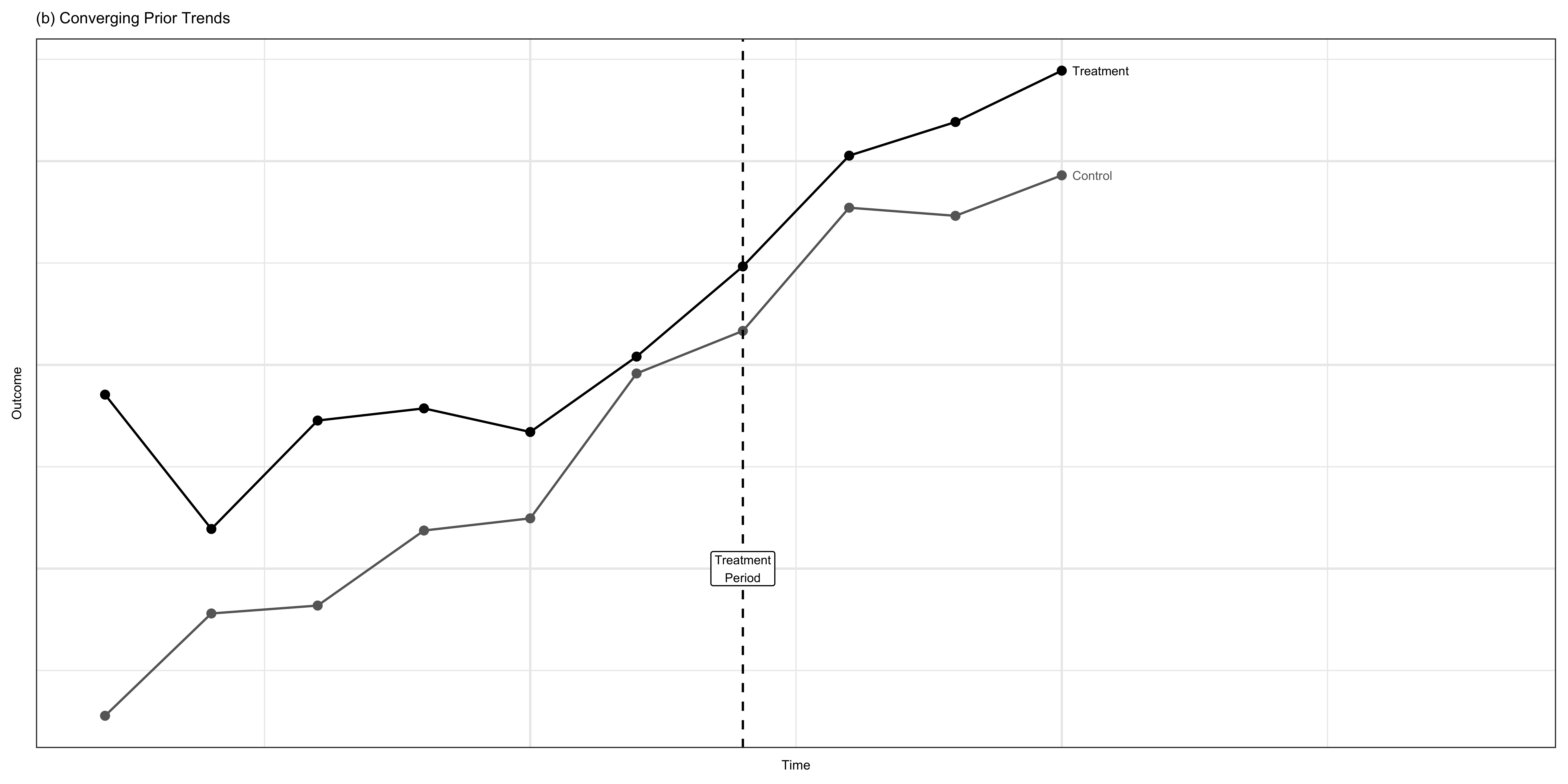
So, how about our example?
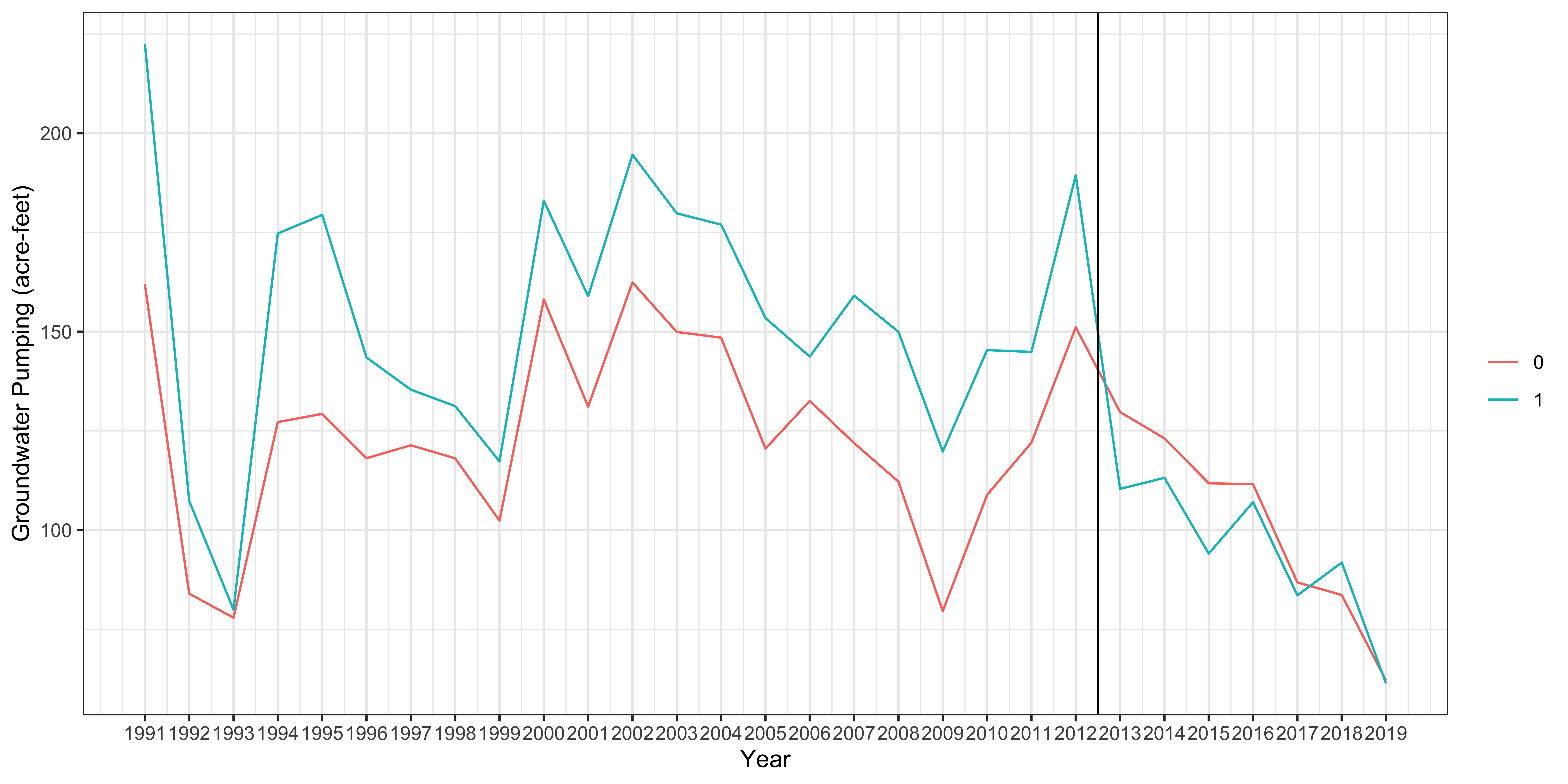
Not too bad. We might want to consider starting from 1993.
Create a fake treament for the wells inside LEMA in 2000.
Estimate the impact of the fake treatment variable:
(
fixest::feols(
af_used ~ I(after_2000 * in_LEMA) + pr + et0 | site + year,
cluster = ~site,
data = pre_lema_data
)
)OLS estimation, Dep. Var.: af_used
Observations: 23,509
Fixed-effects: site: 1,358, year: 20
Standard-errors: Clustered (site)
Estimate Std. Error t value Pr(>|t|)
I(after_2000 * in_LEMA) 1.988322 2.588713 0.768073 0.44258
pr -0.214327 0.017302 -12.387431 < 2.2e-16 ***
et0 -0.005044 0.046476 -0.108533 0.91359
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 39.5 Adj. R2: 0.71128
Within R2: 0.008306Create a fake treament for the wells inside LEMA in 1995.
Estimate the impact of the fake treatment variable:
(
fixest::feols(
af_used ~ I(after_1995 * in_LEMA) + pr + et0 | site + year,
cluster = ~site,
data = pre_lema_data
)
)OLS estimation, Dep. Var.: af_used
Observations: 23,509
Fixed-effects: site: 1,358, year: 20
Standard-errors: Clustered (site)
Estimate Std. Error t value Pr(>|t|)
I(after_1995 * in_LEMA) -2.353117 2.910581 -0.808470 0.41896
pr -0.214146 0.017320 -12.363797 < 2.2e-16 ***
et0 0.007087 0.047450 0.149355 0.88130
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
RMSE: 39.5 Adj. R2: 0.711271
Within R2: 0.008276You can try more years as the starting year of a fake treatment and see what happens.
What if your data spans from 1991 to 2000 with a treatment occuring at 1993?
Let’s look at the regression results:
Code
| (1) |
|---|---|
I(after_1993 * in_LEMA) | -16.386*** |
(3.900) | |
pr | -0.121*** |
(0.026) | |
et0 | 0.114+ |
(0.065) | |
Num.Obs. | 11320 |
R2 | 0.715 |
RMSE | 40.96 |
Std.Errors | by: site |
+ p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |
- So, this tells you that if it was a real treatment of which you want to understand the impact, then you would have suffered significant bias.
- This clearly indicates that DID is by no means perfect and indeed can be very dangerous