| Location | Year | P | Q |
|---|---|---|---|
| Chicago | 2003 | 75 | 2.0 |
| Peoria | 2003 | 50 | 1.0 |
| Milwaukee | 2003 | 60 | 1.5 |
| Madison | 2003 | 55 | 0.8 |
10: Panel Data Methods
Fixed effects (dummy variables) to harness clean variations
Objective
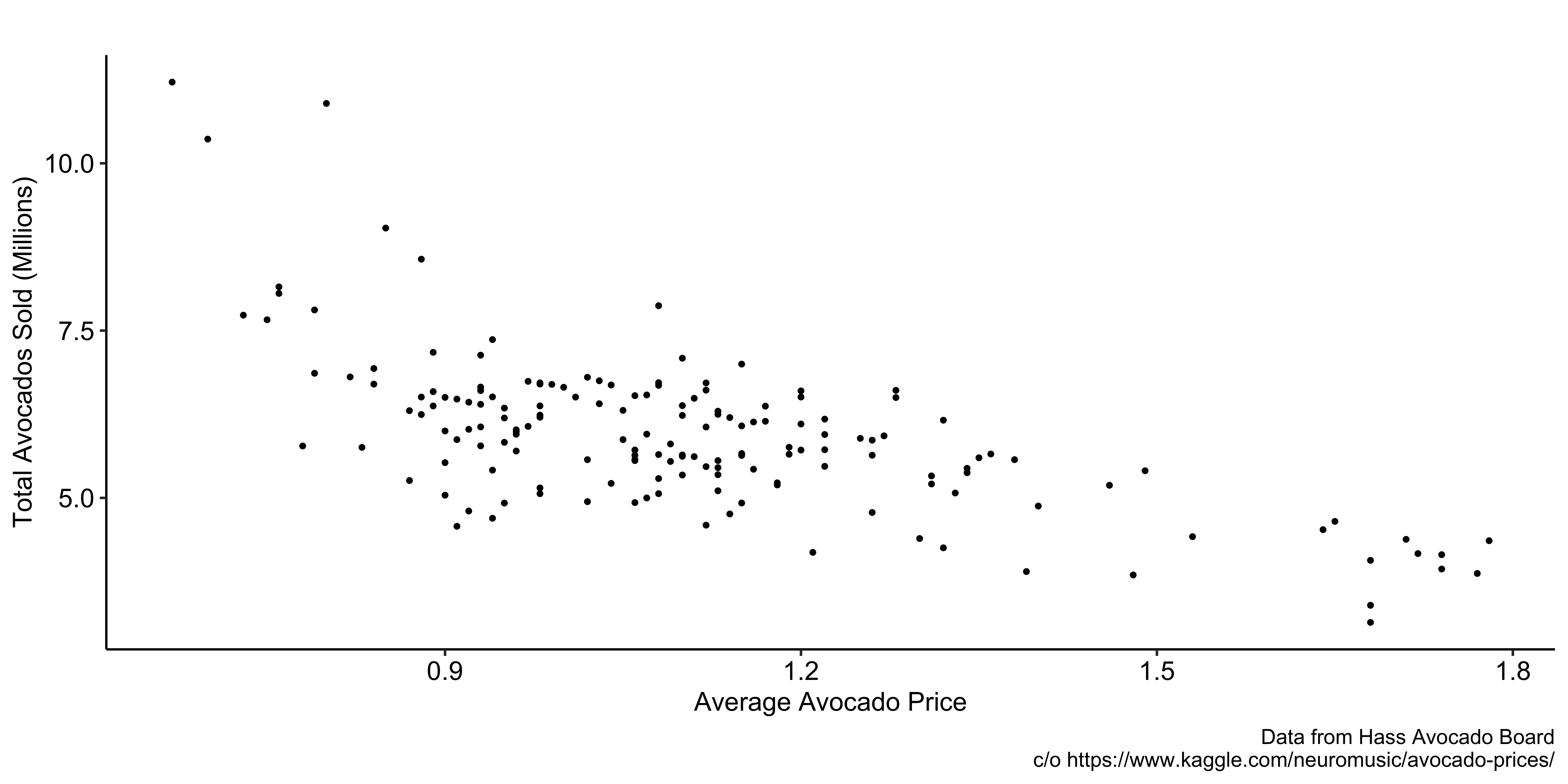
You are interested in understanding the impact of avocado price on its consumption.
Observations
- They are negatively associated with each other
- Avocado sales tend to be lower in weeks where the price of avocados is high.
- Prices tend to be higher in weeks where fewer avocados are sold
Question
If you just regress avocado sales on its price, is the estimation of the coefficient on the pirce unbiased?
Answer
No.
- Reverse causality
- price affects demand
- demand affects price
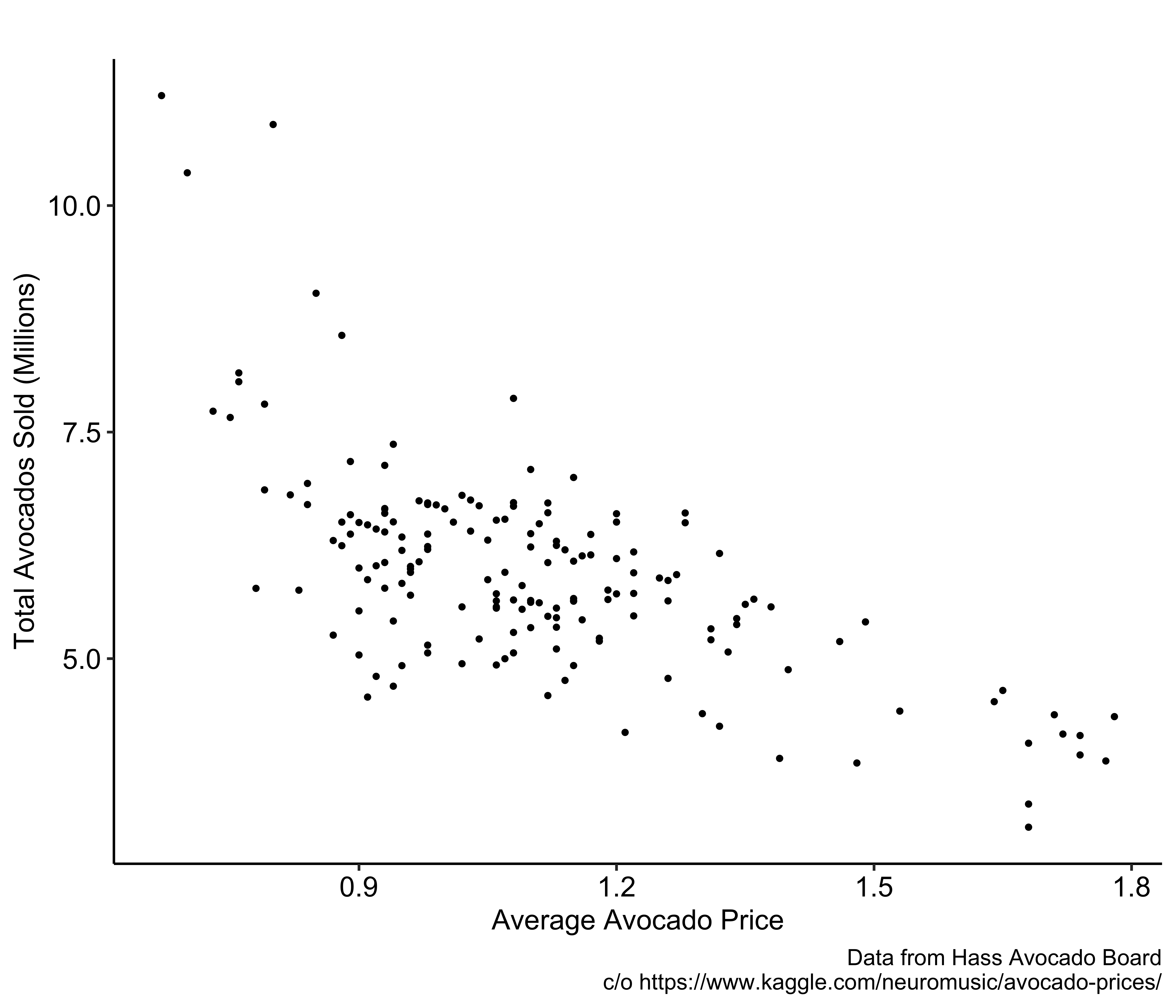
Problem
Reverse Causality: Price affects demand and demand affects price.
contextual knowledge
Now, suppose you learned the following fact after studying the supply and purchasing mechanism on the avocado market:
At the beginning of each month, avocado suppliers make a plan for what avocado prices will be each week in that month, and never change their plans until the next month.
This means that within the same month changes in avocado price every week is not a function of how much avocado has been bought in the previous weeks, effectively breaking the causal effect of demand on price.
So, our estimation strategy would be to just look at the variations in demand and price within individual months, but ignore variations in price between months.
The figure below presents avocado sales and price of avocado in March, 2015. This is an example of clean variations in price (intra-month observations).
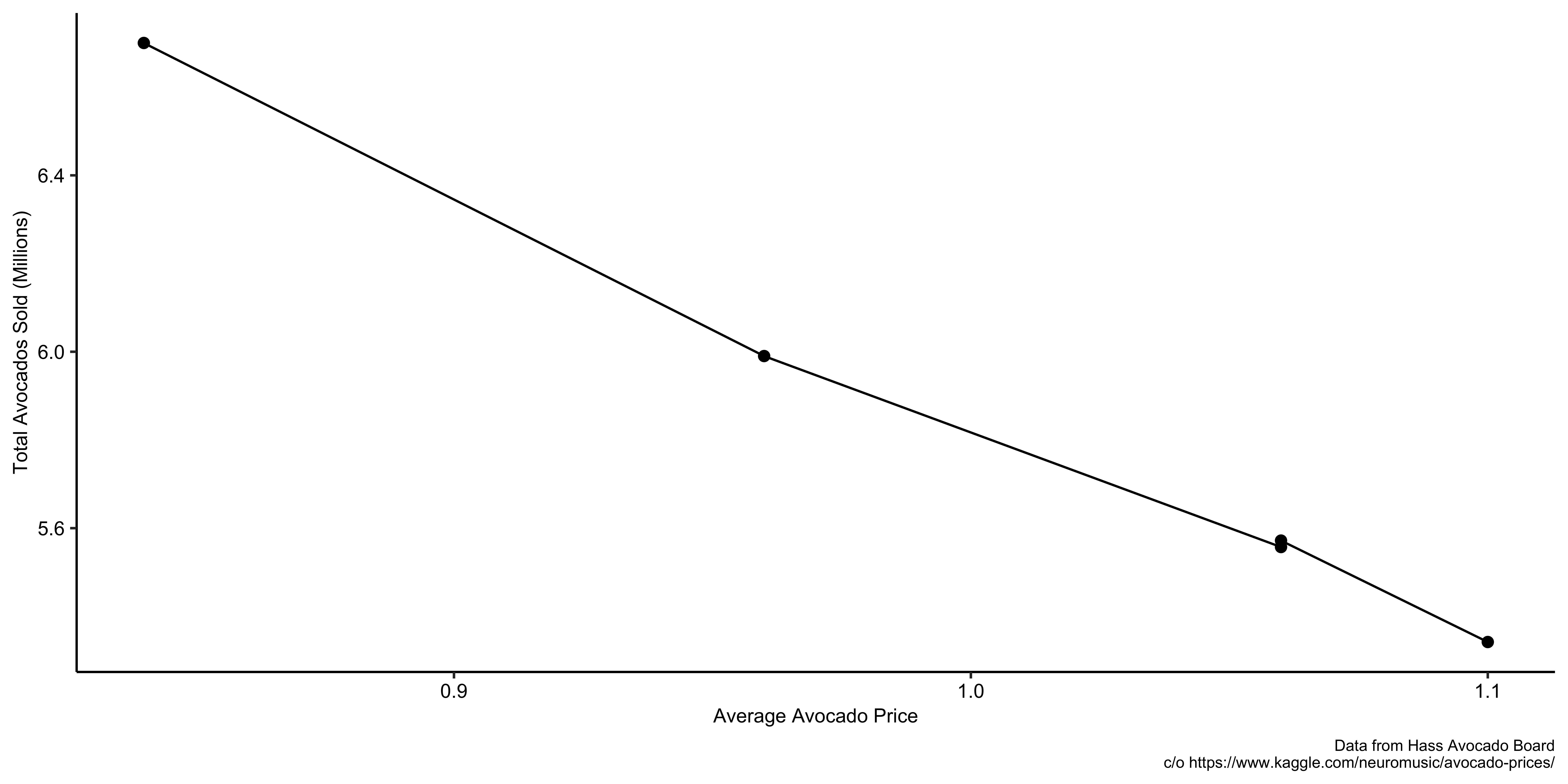
We have three months of avocado purchase and price observed weekly.
Question
What should we do?
Answer
Include month dummy variables.We have two years of avocado purchase and price observed weekly.
Question
What should we do?
Answer
Include month-year dummy variables.
Including month dummy variables will not do it. Because the observations in the same month in two different years are considered to belong to the same group. That is, variations between two different years of the same month will be used for estimation. (e.g., January in 2014 and January in 2015)
Message 1
By understanding the data generating process (knowing how any economic market works), we recognize the problem of simply looking at the relationship between the avocado price and demand to conclude the causal impact of price on demand (reverse causality).
Message 2
We study the context very well and how the avocado market works in California (of course it is not really how CA avocado market works in reality) and make use of the information to identify the “clean” variations in avocado price to identify its impact on demand.