It turns out,
You can proceed exactly the same way as you did before (practically speaking)!!
calculate \((\widehat{\beta}_j-\beta_j)/\widehat{se(\widehat{\beta}_j)}\)
check if the obtained value is greater than (in magnitude) the critical value for the specified significance level under \(t_{n-k-1}\)
But,
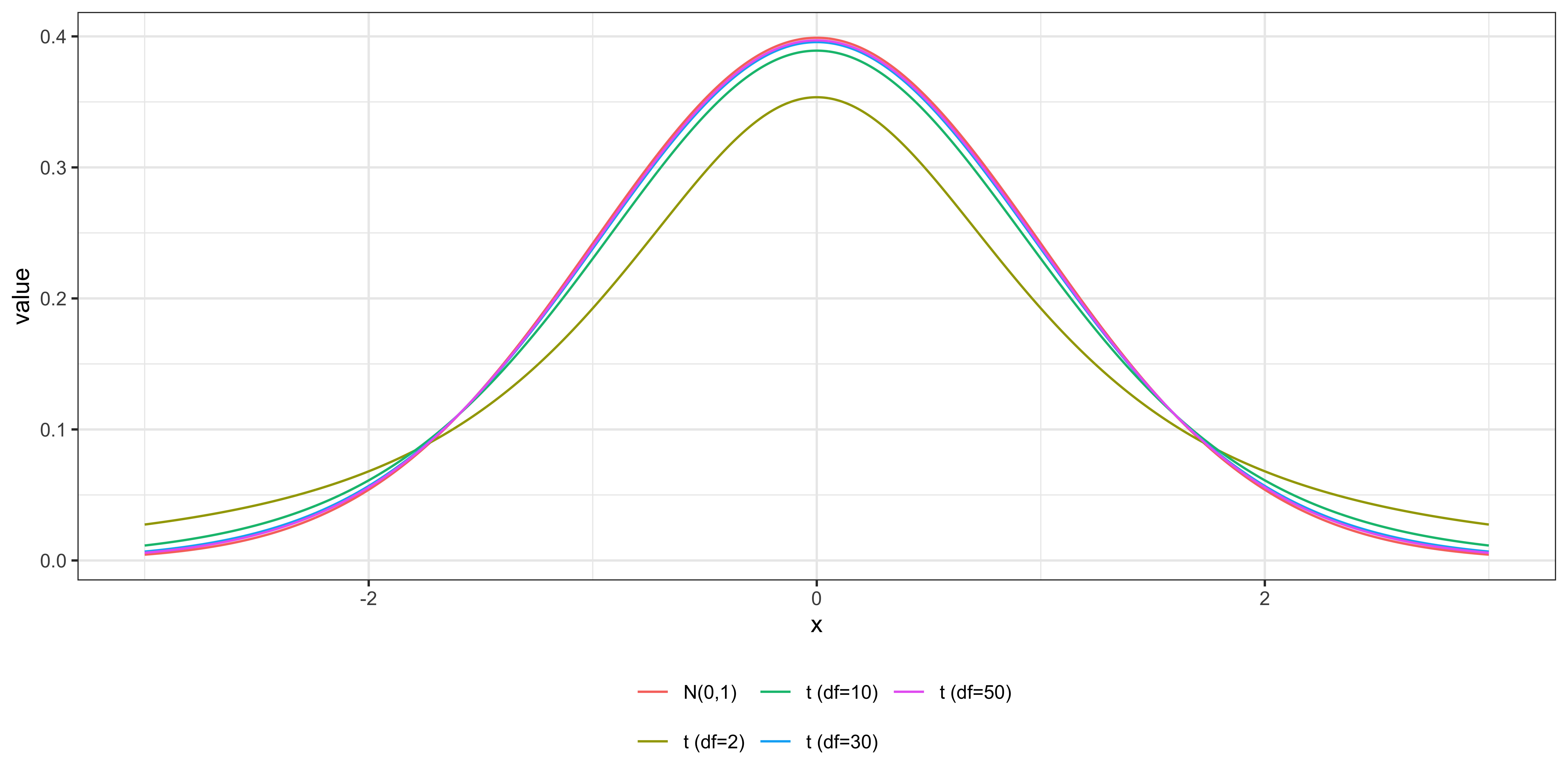
Shouldn’t we use \(N(0,1)\) when you find the critical value?
Since \(t_{n-k-1}\) and \(N(0,1)\) are almost identical when \(n\) is large, there is very little error in using \(t_{n-k-1}\) instead of \(N(0,1)\) to find the critical value.
The consistency of the default estimation of \(\widehat{Var(\widehat{\beta})}\) DOES require the homoskedasticity assumption (MLR.5).
In other words, the problem of using the default variance estimator under the hteroskedasticity does not go away even when the sample size is large.
So, we should use heteroskedasticity-robust or cluster-robust standard error estimators even when the sample size is large