07: Econometric Modeling
Various functional forms
Model
\[\begin{align} log(y_i)= \beta_0+\beta_1 x_i + u_i \notag \end{align}\]Calculus
Differentiating the both sides wrt \(x_i\),
\[\begin{align} \frac{1}{y_i}\cdot\frac{\partial y_i}{\partial x_i} = \beta_1 \Rightarrow \frac{\Delta y_i}{y_i} = \beta_1 \Delta x_i \notag \end{align}\]Interpretation
\(\beta_1\) measures a percentage change in \(y_i\) (once multiplied by 100) when \(x_i\) is increased by one unit
Model
\[\begin{align} log(wage)=\beta_0 + \beta_1 educ + u \notag \end{align}\]Calculus
Differentiating both sides with respect to \(educ\),
\[\begin{align} \frac{1}{wage} \frac{\partial wage}{\partial educ} = \beta_1 \Rightarrow \frac{\Delta wage}{wage} = \beta_1\Delta educ\notag \end{align}\]Interpretation
If education increases by 1 year \((\Delta educ=1)\), then wage increases by \(\beta_1*100\%\) \((\frac{\Delta wage}{wage}=\beta_1)\)
When you estimate the following model using the wage dataset:
\[log(wage)=\beta_0 + \beta_1 educ + u \notag\]
Then, the estimated equation is the following:
\[\begin{align} \widehat{log(wage)}=0.584+0.083 educ \notag \end{align}\] \[\begin{align} E[\widehat{wage}]=e^{0.584+0.083 educ} \end{align}\]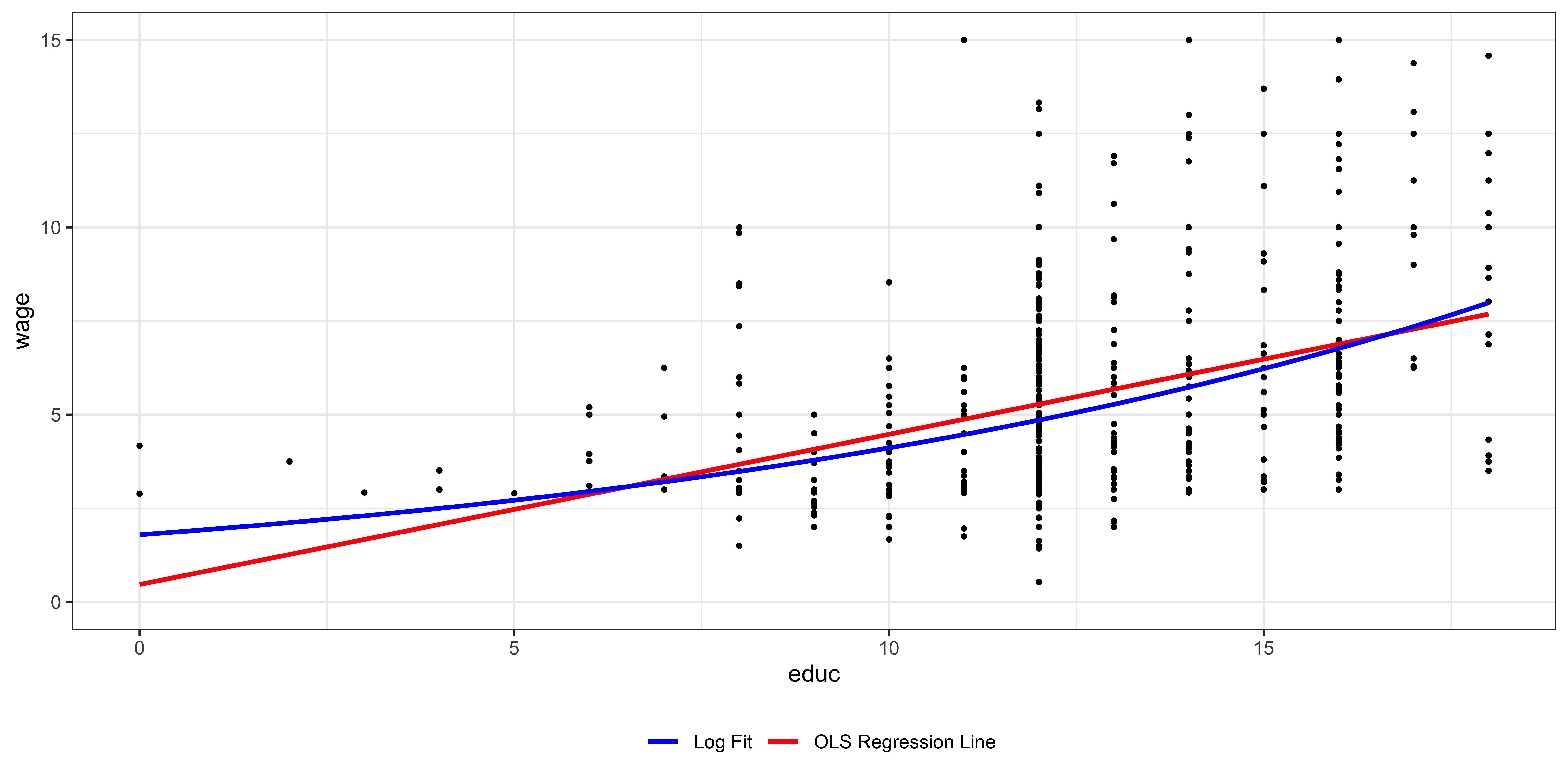
Model
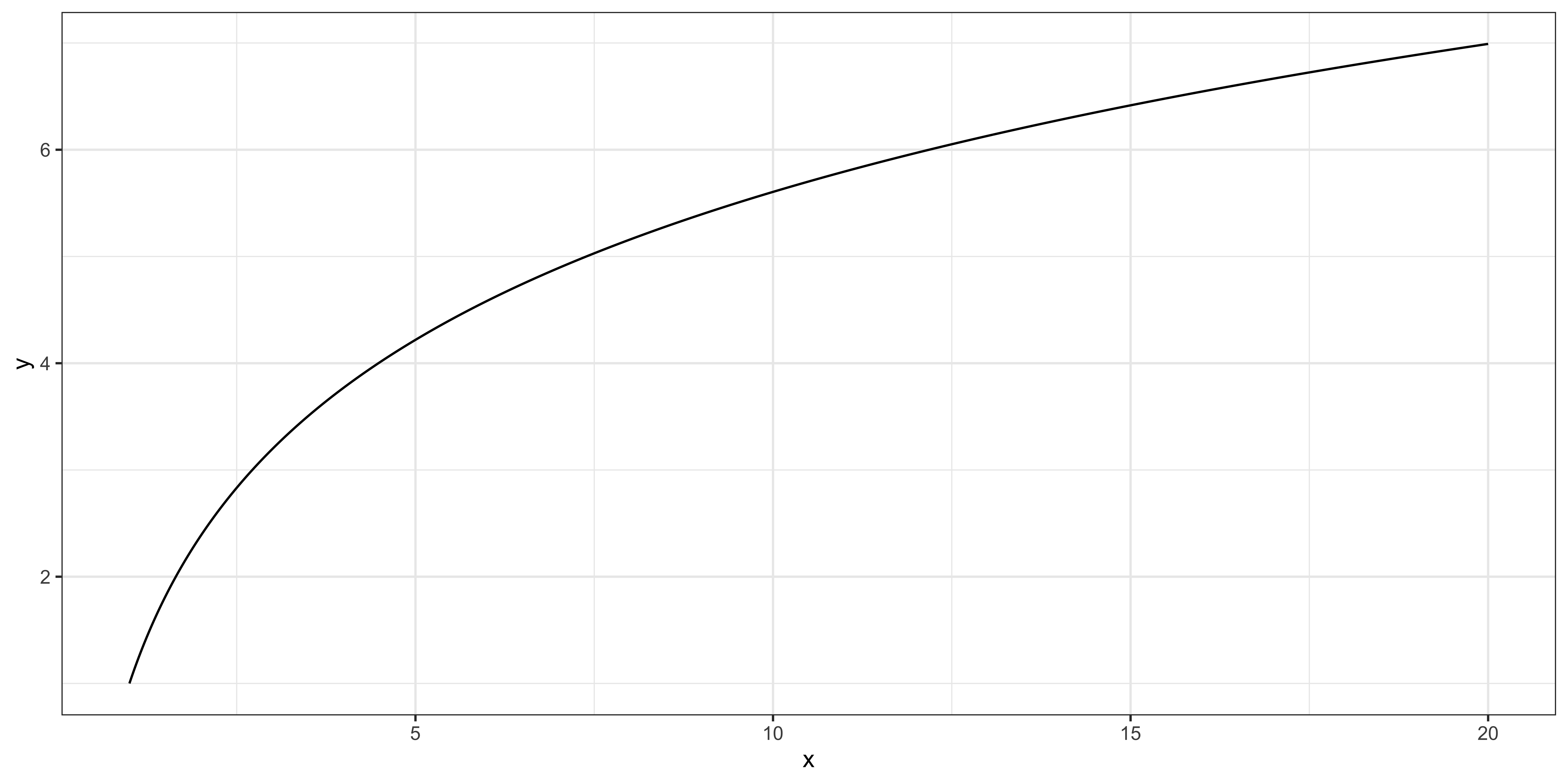
\[\begin{align} y_i= \beta_0+\beta_1 log(x_i) +u_i \notag \end{align}\]Calculus
Differentiating the both sides wrt \(x_i\),
\[\begin{align} \frac{\partial y_i}{\partial x_i} = \frac{\beta_1}{x_i} \Rightarrow \Delta y_i = \beta_1\frac{\Delta x_i}{x_i} \notag \end{align}\]Interpretation
When \(x\) increases by 0.01 (\(1\%\)) \(y\) increases by \(\beta_1 \times 0.01\).
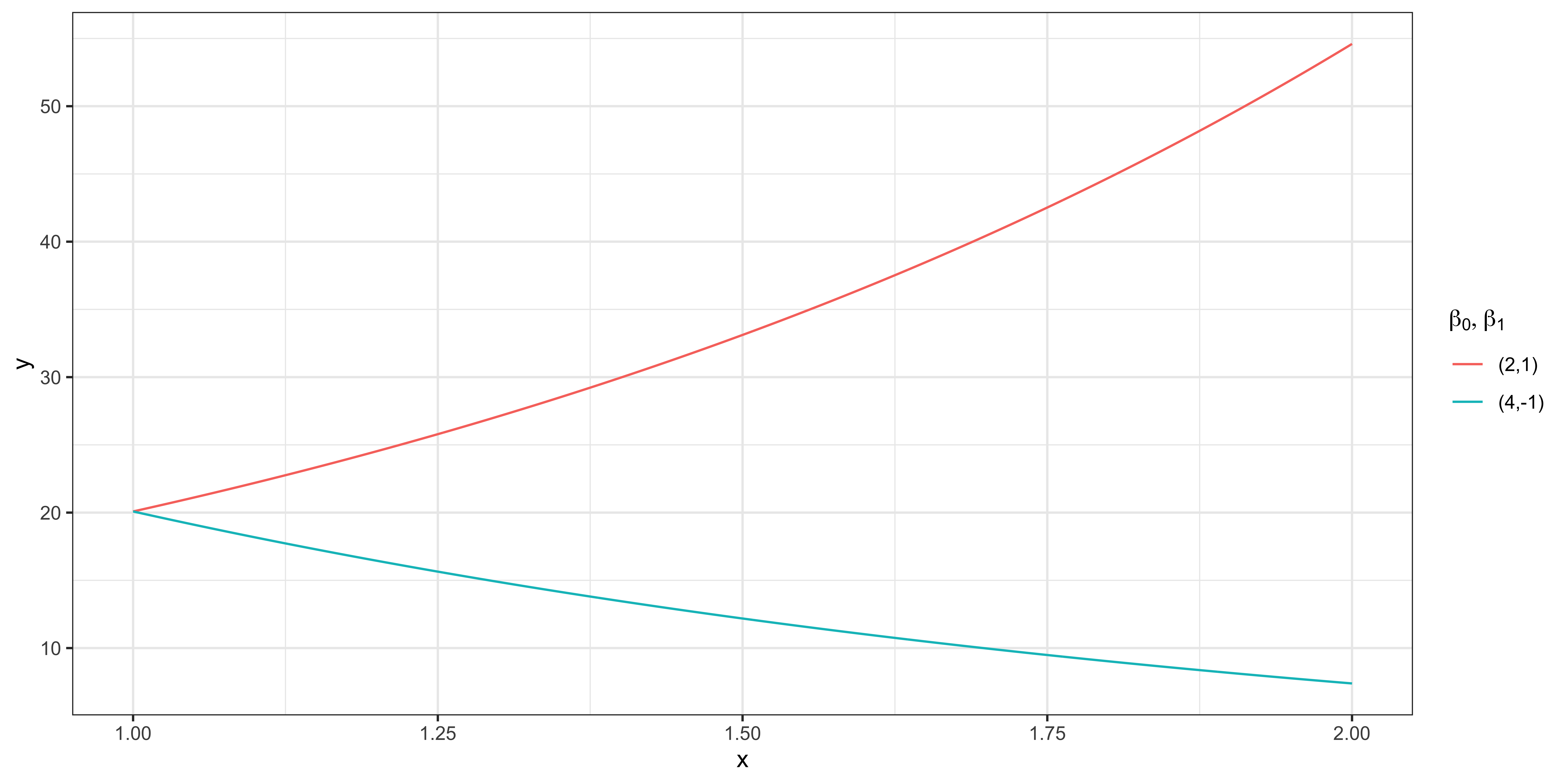
\[y = \beta_0 + \beta_1 log(x) = 1 + 2 \times log(x)\]
Model
\[\begin{align} log(y_i)= \beta_0+\beta_1 log(x_i) +u_i \notag \end{align}\]Calculus
Differentiating the both sides wrt \(x_i\),
\[\begin{align} \frac{\partial y_i}{y_i}/\frac{\partial x_i}{x_i} = \beta_1 \Rightarrow \frac{\Delta y_i}{y_i} = \beta_1 \frac{\Delta x_i}{x_i}\notag \end{align}\]Interpretation
A percentage change in \(x\) would result in a \(\beta_1\) percentage change in \(y_i\) (constant elasticity)
Model
\(y_i= \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + u_i\)
Calculus
Differentiating the both sides wrt \(x_i\),
\(\frac{\partial y_i}{\partial x_i} = \beta_1 + 2*\beta_2 x_i\Rightarrow \Delta y_i = (\beta_1 + 2*\beta_2 x_i)\Delta x_i\)
Interpretation
When \(x\) increases by 1 unit \((\Delta x_i=1)\), \(y\) increases by \(\beta_1 + 2*\beta_2 x_i\)
Quadratic functional form is quite flexible.
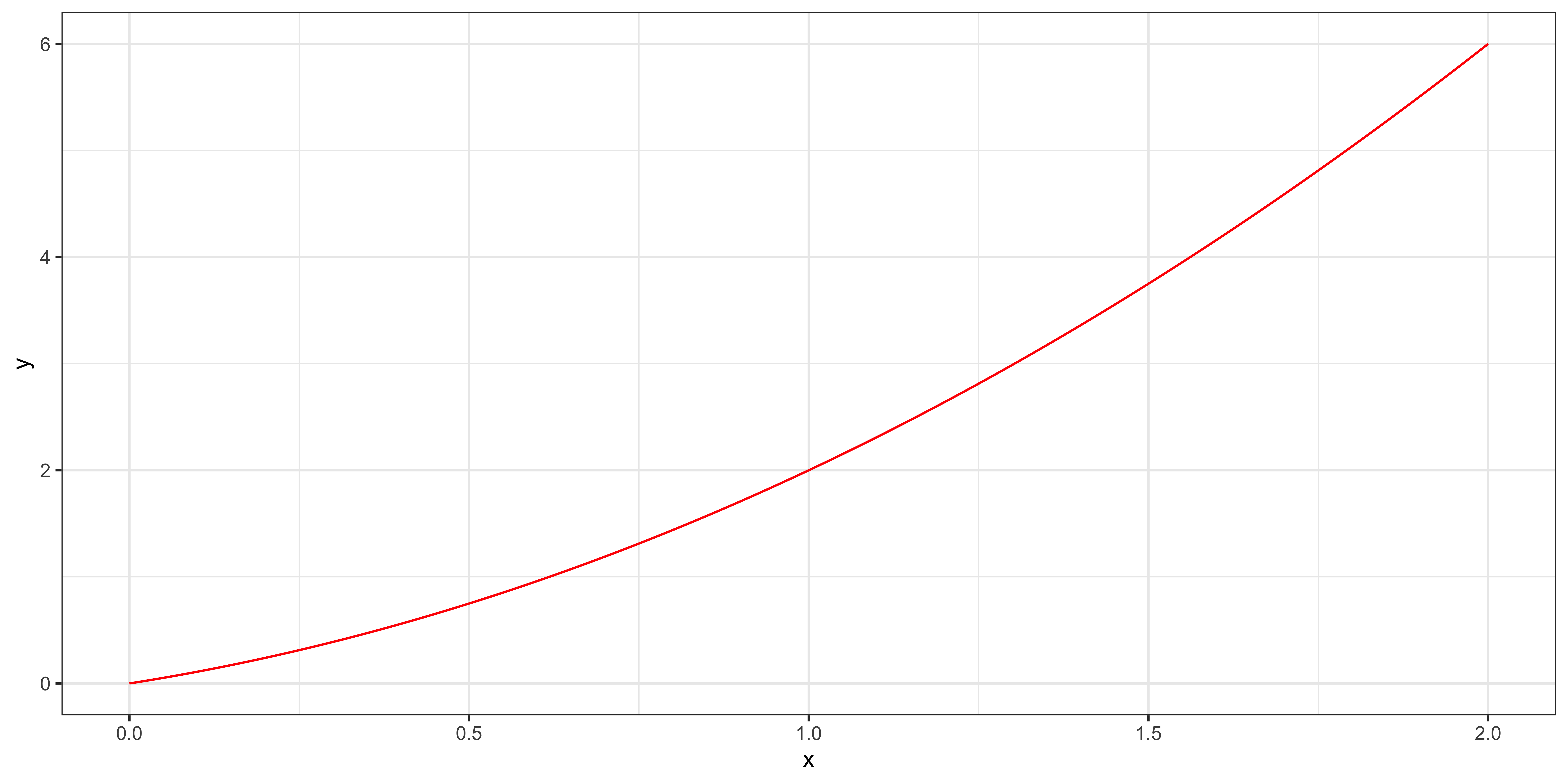
\(y = x + x^2\) \((\beta_1 = 1, \beta_2 = 1)\)
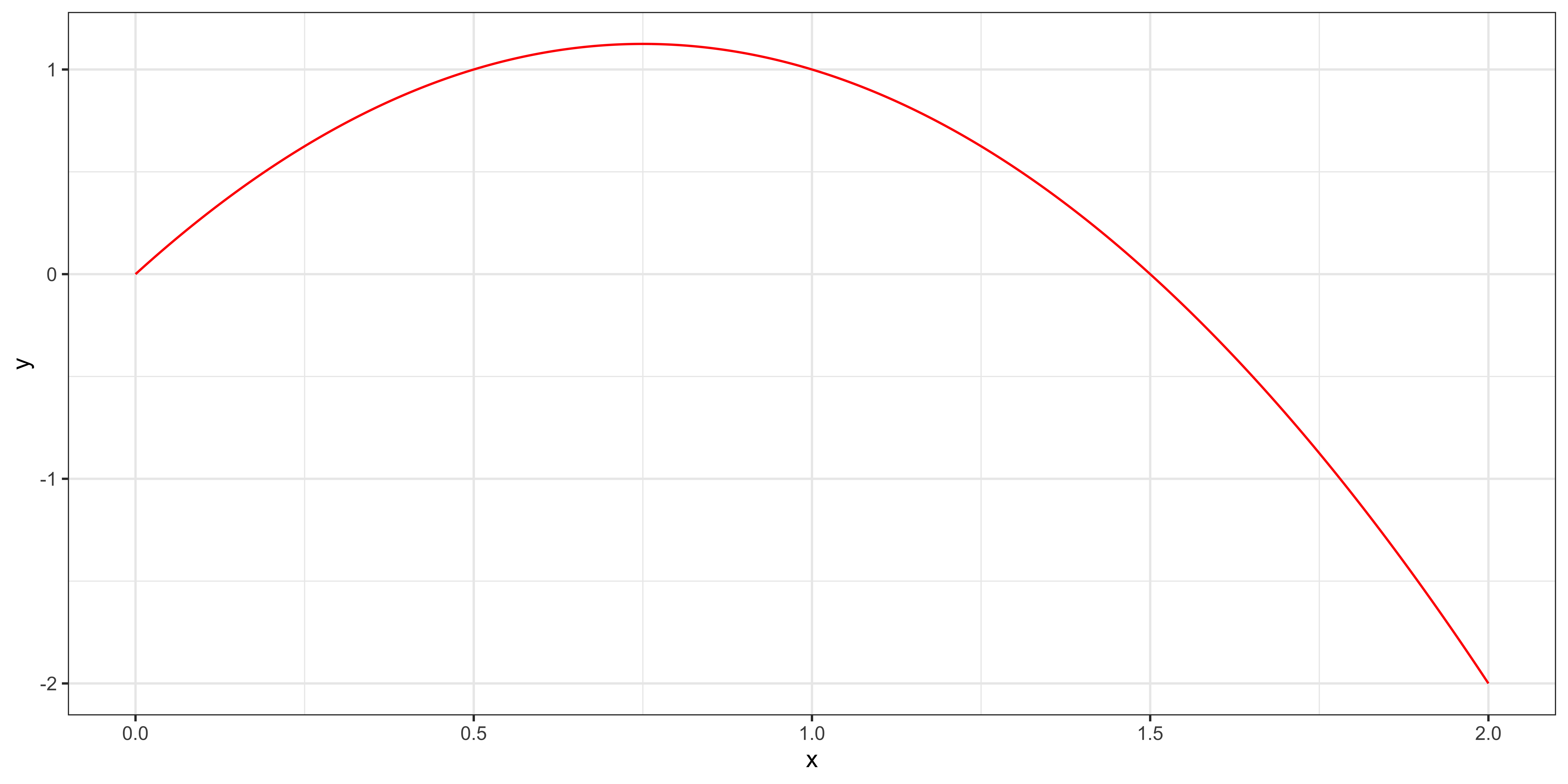
\(y = 3x-2x^2\) \((\beta_1 = 3, \beta_2 = -2)\)
Education impacts of income
The marginal impact of education (the impact of a small change in education on income) may differ what level of education you have had:
How much does it help to have two more years of education when you have had education until elementary school?
How much does it help to have two more years of education when you have graduated a college?
How much does it help to spend two more years as a Ph.D student if you have already spent six years in a Ph.D program
Observation
The marginal impact of education does not seem to be linear.
When you want to include a variable that is a transformation of an existing variable, you can use I() function in which you write the mathematical expression of the desired transformation.
Estimated Model
\(wage = 5.60 - 2.12\times female -0.416\times educ + 0.039\times educ^2\)
According to the estimated model, the marginal impact of \(educ\) is:
\(\frac{\partial wage}{\partial educ} = -0.416+0.039\times 2\times educ\)
When \(educ = 4\), additional year of education is going to increase hourly wage by -0.104 on average
When \(educ = 10\), additional year of education is going to increase hourly wage by 0.364 on average
Interaction terms
A variable that is a multiplication of two variables
Example
\(educ\times exper\)
A model with an interaction term
\(wage = \beta_0 + \beta_1 exper + \beta_2 educ \times exper + u\)
Marginal impact of education:
\(\frac{\partial wage}{\partial exper} = \beta_1+\beta_2\times educ\)
Implications
The marginal impact of experience depends on education
\(\beta_1\): the marginal impact of experience when \(educ=0\)
if \(\beta_2>0\): additional year of experience is worth more when you have more years of education
Just like the quadratic case with \(educ^2\), you can use I().
Estimated Model
\(wage = 6.121 - 2.418 \times female - 0.188 \times exper + 0.020 \times educ \times exper\)
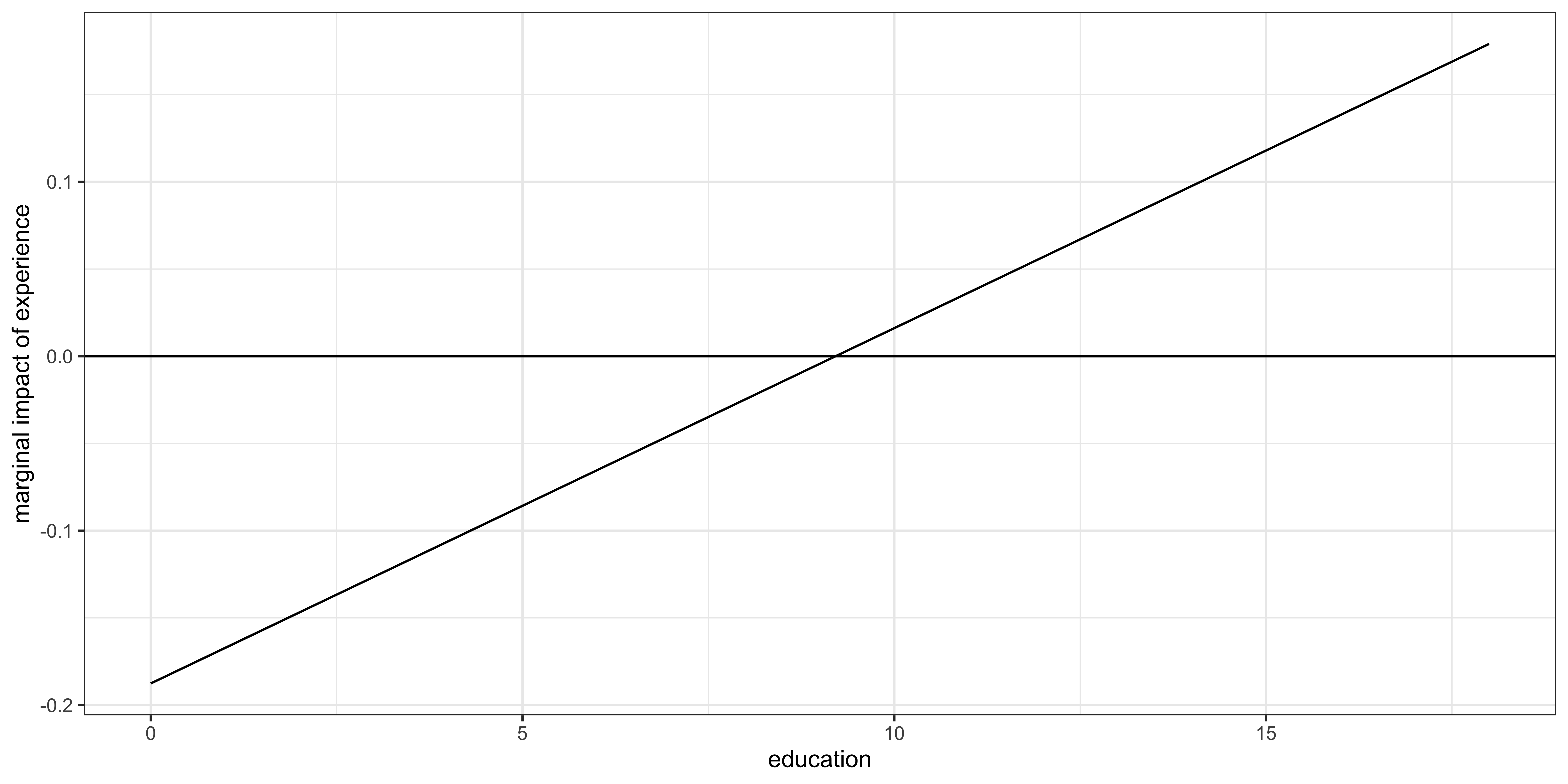
Marginal impact of experience
\(\frac{\partial wage}{\partial exper} = - 0.188 + 0.020 \times educ\)
Marginal impact of \(exper\):
Histogram of education:
Just like the case of the quadratic specification of education, marginal impact of experience is not constant
We can test if the marginal impact of experience is statistically significant for a given level of education
- When \(educ=10\), \(\frac{\partial wage}{\partial exper} = - 0.188 + 0.020 \times 10=0.012\)
- When \(educ=15\), \(\frac{\partial wage}{\partial exper} = - 0.188 + 0.020 \times 15=0.112\)
Question
Does additional year of experience has a statistically significant impact (positive or negative) if your current education level is 10
Hypothesis
\(H_0\): \(\hat{\beta}_{exper} + \hat{\beta}_{exper\_educ} \times 10=0\)
\(H_1\): \(\hat{\beta}_{exper} + \hat{\beta}_{exper\_educ} \times 10=0\)
Including qualitative information
Issue
How do we include qualitative information as an independent variable?
Examples
male or female (binary)
married or single (binary)
high-school, college, masters, or Ph.D (more than two states)
Example
Model
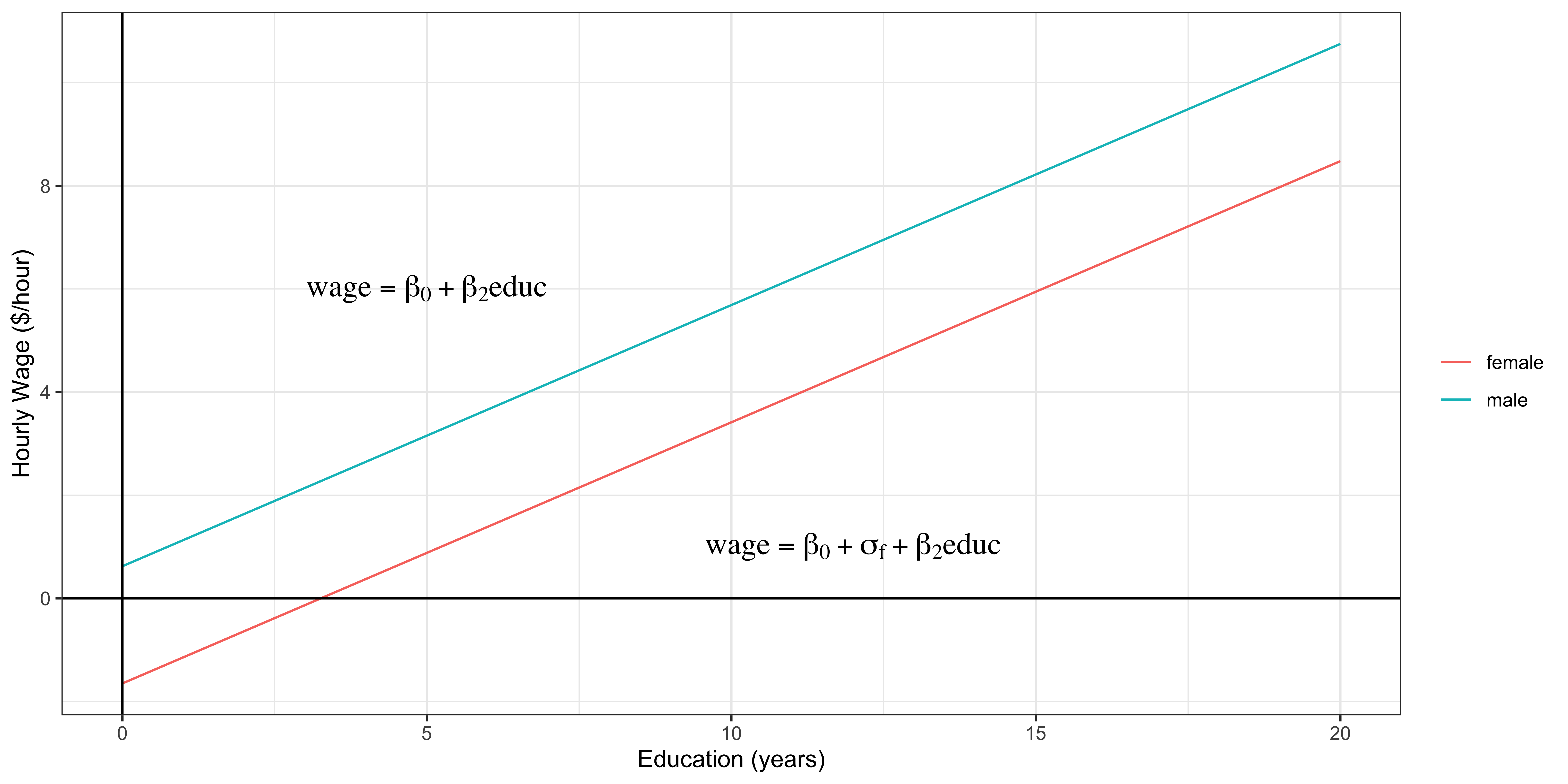
\(wage = \beta_0 +\sigma_f female +\beta_2 educ + u\)
Interpretation
female: \(E[wage|female=1,educ] = \beta_0 + \sigma_f +\beta_2 educ\)male: \(E[wage|female=0,educ] = \beta_0 + \beta_2 educ\)
This means that
\(\sigma_f = E[wage|female=1,educ]-E[wage|female=0,educ]\)
Verbally,
\(\sigma_f\) is the difference in the expected wage conditional on education between female and male
\(\sigma_f\) measures how much more (less) female workers make compared to male workers ( baseline ) if they were to have the same education level
R implementation
Interpretation
Female workers make -2.2733619 ($/hour) less than male workers on average even though they have the same education level.
Model
\(wage = \beta_0 +\sigma_m male +\beta_2 educ + u\)
Interpretation
male: \(E[wage|male = 1,educ] = \beta_0 + \sigma_m +\beta_2 educ\)female: \(E[wage|male = 0,educ] = \beta_0 + \beta_2 educ\)
This means that
\(\sigma_m = E[wage|male=1,educ]-E[wage|male=0,educ]\)
Verbally,
\(\sigma_m\) is the difference in the expected wage conditional on education between female and male
\(\sigma_m\) measures how much more (less) male workers make compared to female workers (baseline) if they were to have the same education level
Regression results
Interpretation
Male workers make NA ($/hour) more than female workers on average even though they have the same education level.
What do you think will happen if we include both male and female dummy variables?
Answer
They contain redundant information
Indeed, including both of them along with the intercept would cause perfect collinearity problem
So, you need to drop either one of them
In the model, \(intercept = male + female\), which causes perfec collinearity.
Here is what happens if you include both:
One of the variables that cause perfect collinearity is automatically dropped.
Interactions with a dummy variable
In the previous example, the impact of education on wage was modeled to be exactly the same
Can we build a more flexible model that allows us to estimate the differential impacts of education on wage between male and female?
A more flexible model
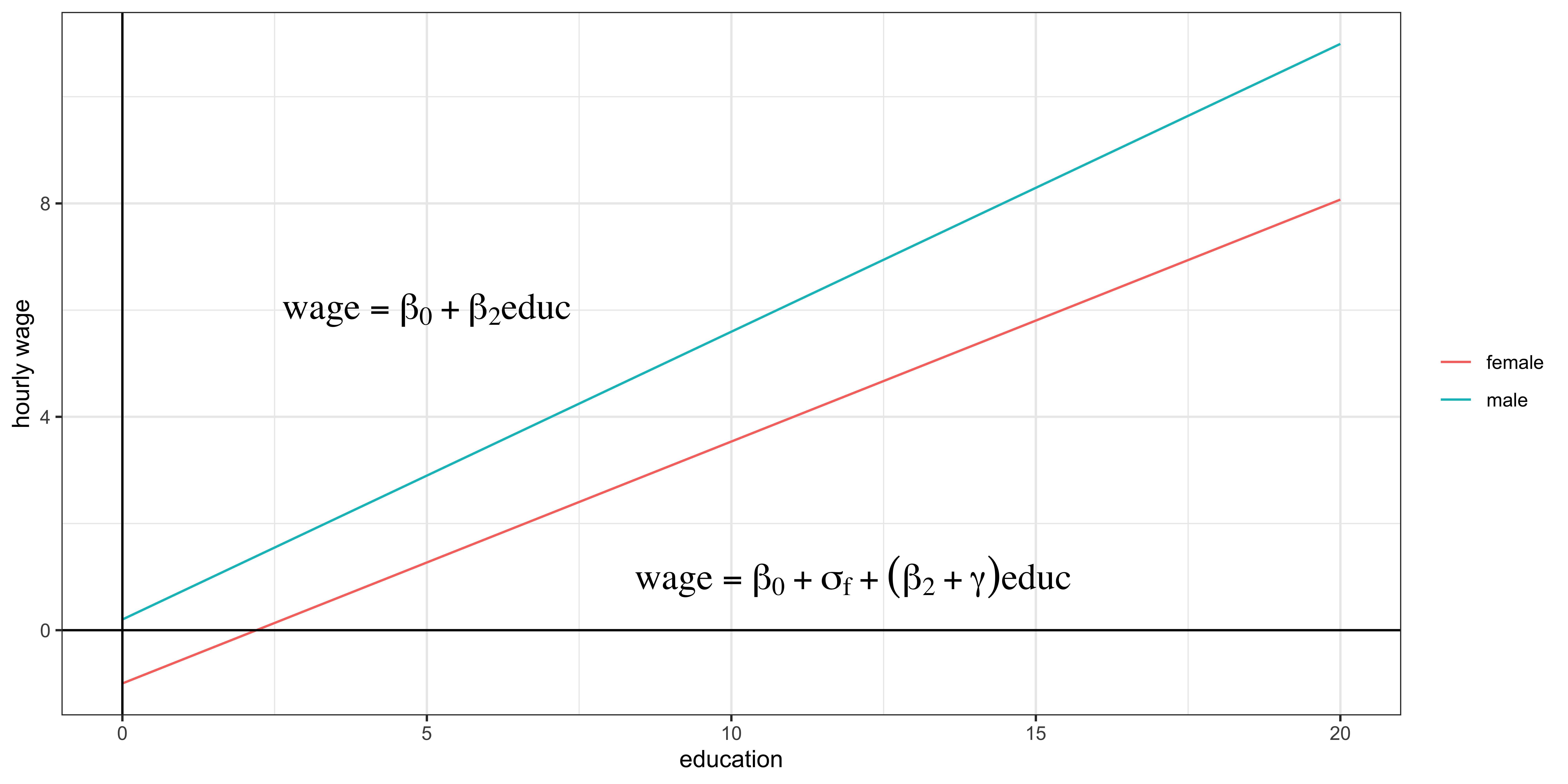
\(wage = \beta_0 + \sigma_f female +\beta_2 educ + \gamma female\times educ + u\)
female: \(E[wage|female=1,educ] = \beta_0 + \sigma_f +(\beta_2+\gamma) educ\)male: \(E[wage|female=0,educ] = \beta_0 + \beta_2 educ\)
Interpretation
For female, education is more effective by \(\gamma\) than it is for male.
The marginal benefit of education is 0.086 ($/hour) less for females workers than for male workers on average.