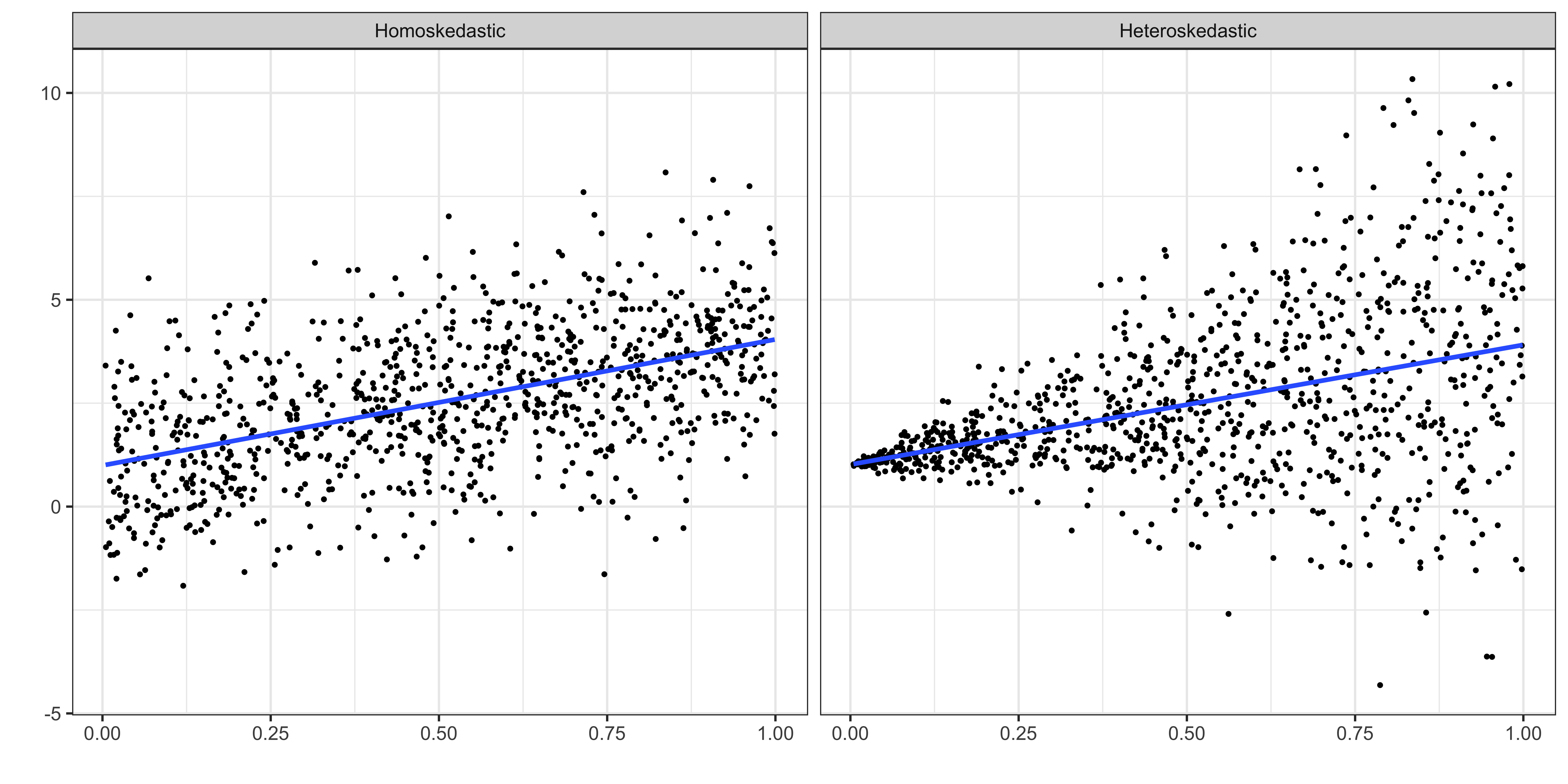
Homoskedasticity
\(Var(u|x) = \sigma^2\)
Heteroskedasticity
\(Var(u|x) = f(x)\)
What are the consequences of assuming the error is homoskedastic when it is heteroskedastic in reality?
We learned that when the homoskedasticity assumption holds, then,
\(Var(\widehat{\beta}_j) = \frac{\sigma^2}{SST_x(1-R^2_j)}\)
We used the following as the estimator of \(Var(\widehat{\beta}_j)\)
\(\frac{\widehat{\sigma}^2}{SST_x(1-R^2_j)}\) where \(\widehat{\sigma}^2 = \frac{\sum_{i=1}^{N} \widehat{u}_i^2}{N-k-1}\)
Important
By default , R and other statistical software uses this formula to get estimates of the variance of \(\widehat{\beta}_j\).
But, under heteroskedasticity,
\(Var(\widehat{\beta}_j) \ne \frac{\sigma^2}{SST_x(1-R^2_j)}\)
So, what are the consequences of using \(\widehat{Var(\widehat{\beta}_j)}=\frac{\widehat{\sigma}^2}{SST_x(1-R^2_j)}\) under heteroskedasticity?
\(\;\;\;\;\downarrow\)
Your hypothesis testing is going to be biased!!
Let’s run MC simulations to see the consequence of ignoring heteroskedasticity.
Model
\(y = 1 + \beta x + u\), where \(\beta = 0\)
Test of interest
\[y=\beta_0+\beta_1 x + v\]
Consequence of ignoring heteroskedasticity
We rejected the null hypothesis 10.8% of the time, instead of \(5\%\).
So, in this case, you are more likely to claim that \(x\) has a statistically significant impact than you are supposed to.
The use of the formula \(\frac{\widehat{\sigma}^2}{SST_x(1-R^2_j)}\) seemed to (over/under)-estimate the true variance of the OLS estimators?
In general, the direction of bias is ambiguous.
Now, we understand the consequence of heteroskedasticity:
\(\frac{\widehat{\sigma}^2}{SST_x(1-R^2_j)}\) is a biased estimator of \(Var(\widehat{\beta})\), which makes any kind of testings based on it invalid.
Can we credibly estimate the variance of the OLS estimators?
White-Huber-Eicker heteroskedasticity-robust standard error estimator
Heteroskedasticity-robust standard error estimator
\(\widehat{Var(\widehat{\beta}_j)} = \frac{\sum_{i=1}^n \widehat{r}^2_{i,j} \widehat{u}^2_i}{SSR^2_j}\)
Note
We spend NO time to try to understand what’s going on with the estimator.
What you need is
Here is the well-accepted procedure in econometric analysis:
Estimate the model using OLS (you do nothing special here)
Assume the error term is heteroskedastic and estimate the variance of the OLS estimators
Replace the estimates from \(\widehat{Var(\widehat{\beta})}_{default}\) with those from \(\widehat{Var(\widehat{\beta})}_{robust}\) for testing
But, we do not replace coefficient estimates (remember, coefficient estimation is still unbiased under heteroskedasticity)
Let’s run a regression using MLB1.dta.
We use
the stats::vcov() function to estimate heteroskedasticity-robust standard errors
the fixest::se() function from the fixest package to estimate heteroskedasticity-robust standard errors (you can always get SE from VCOV)
the summary() function to do tests of \(\beta_j = 0\)
General Syntax
Here is the general syntax to obtain various types of VCOV (and se) esimaties:
heteroskedasticity-robust standard error estimation
Specifically for White-Huber heteroskedasticity-robust VCOV and se estimates,
Default
Heteroskedasticity-robust
In presenting the regression results in a nicely formatted table, we used modelsummary::msummary().
We can easily swap the default se with the heteroskedasticity-robust se using the statistic_override option in msummary().
| (1) | (2) | |
|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||
| (Intercept) | 11.042*** | 11.042*** |
| (0.343) | (0.343) | |
| years | 0.166*** | 0.166*** |
| (0.013) | (0.013) | |
| bavg | 0.005*** | 0.005*** |
| (0.001) | (0.001) | |
| Num.Obs. | 353 | 353 |
| R2 | 0.367 | 0.367 |
| RMSE | 0.94 | 0.94 |
| Std.Errors | IID | IID |
Alternatively, you could add the vcov option like below inside fixest::feols(). Then, you do not need statistic_override option to override the default VCOV estimates.
| (1) | |
|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |
| (Intercept) | 11.042*** |
| (0.704) | |
| years | 0.166*** |
| (0.018) | |
| bavg | 0.005+ |
| (0.003) | |
| Num.Obs. | 353 |
| R2 | 0.367 |
| RMSE | 0.94 |
| Std.Errors | Heteroskedasticity-robust |
Does the heteroskedasticity-robust se estimator really work? Let’s see using MC simulations:
Okay, not perfect. But, certainly better.
College GPA: cluster by college
\(GPA_{col} = \beta_0 + \beta_1 income + \beta_2 GPA_{hs} + u\)
Eduction Impacts on Income: cluster by individual
Your observations consist of 500 individuals with each individual tracked over 10 years
Because of some unobserved (omitted) individual characteristics, error terms for time-series observations within an individual might be correlated.
Are the OLS estimators of the coefficients biased in the presence of clustered error?
Are \(\widehat{Var(\widehat{\beta})}_{default}\) unbiased estimators of \(Var(\widehat{\beta})\)?
Which has more information?
Consequences
If you were to use \(\widehat{Var(\widehat{\beta})}_{default}\) to estimate \(Var(\widehat{\beta})\) in the presence of clustered error, you would (under/over)-estimate the true \(Var(\widehat{\beta})\).
This would lead to rejecting null hypothesis (more/less) often than you are supposed to.
Here are the conceptual steps of the MC simulations to see the consequence of clustered error.
\[ \begin{aligned} y = \beta_0 + \beta_1 x + u \end{aligned} \]
Important
There exist estimators of \(Var(\widehat{\beta})\) that take into account the possibility that errors are clustered.
We call such estimators cluster-robust variance covariance estimator denoted as \((\widehat{Var(\widehat{\beta})}_{cl})\)
We call standart error estimates from such estimators cluster-robust standard error estimates
I neither derive nor show the mathematical expressions of these estimators.
This is what you need to do
understand the consequence of clustered errors
know there are estimators that are appropriate under clustered error
know that the estimators we will learn take care of heteroskedasticity at the same time (so, they really are cluster- and heteroskedasticity-robust standard error estimators)
know how to use the estimators in \(R\) (or some other software)
Cluster-robust standard error
Similar with the vcov option for White-Huber heteroskedasticity-robust se, we can use the cluster option to get cluster-robust se.
Before an R demonstration
Let’s take a look at the MLB data again.
nl: the group variable we cluster around (1 if in the National league, 0 if in the American league).Step 1
Run a regression
Step 2
Apply vcov() or se() with the cluster = option.
Default
Cluster-robust standard error
Just like the heteroskedasticity-present case before,
Estimate the model using OLS (you do nothing special here)
Assume the error term is clustered and/or heteroskedastic, and estimate the variance of the OLS estimators \((Var(\widehat{\beta}))\) using cluster-robust standard error estimators
Replace the estimates from \(\widehat{Var(\widehat{\beta})}_{default}\) with those from \(\widehat{Var(\widehat{\beta})}_{cl}\) for testing
But, we do not replace coefficient estimates.
Let’s run MC simulations to see if the use of the cluster-robust standard error estimation method works
Well, we are still rejecting too often than we should, but it is much better than the default VCOV estimator that rejected 74% of the time.
Important
Better. But, we are still over-rejecting. Don’t forget it is certainly better than using the default!