01-1: Univariate Regression: Introduction
Why do we want ceteris paribus causal impact?
Quality of College
You
- have been admitted to University A (better, more expensive) and B (worse, less expensive)
- are trying to decide which school to attend
- are interested in knowing a boost in your future income to make a decision
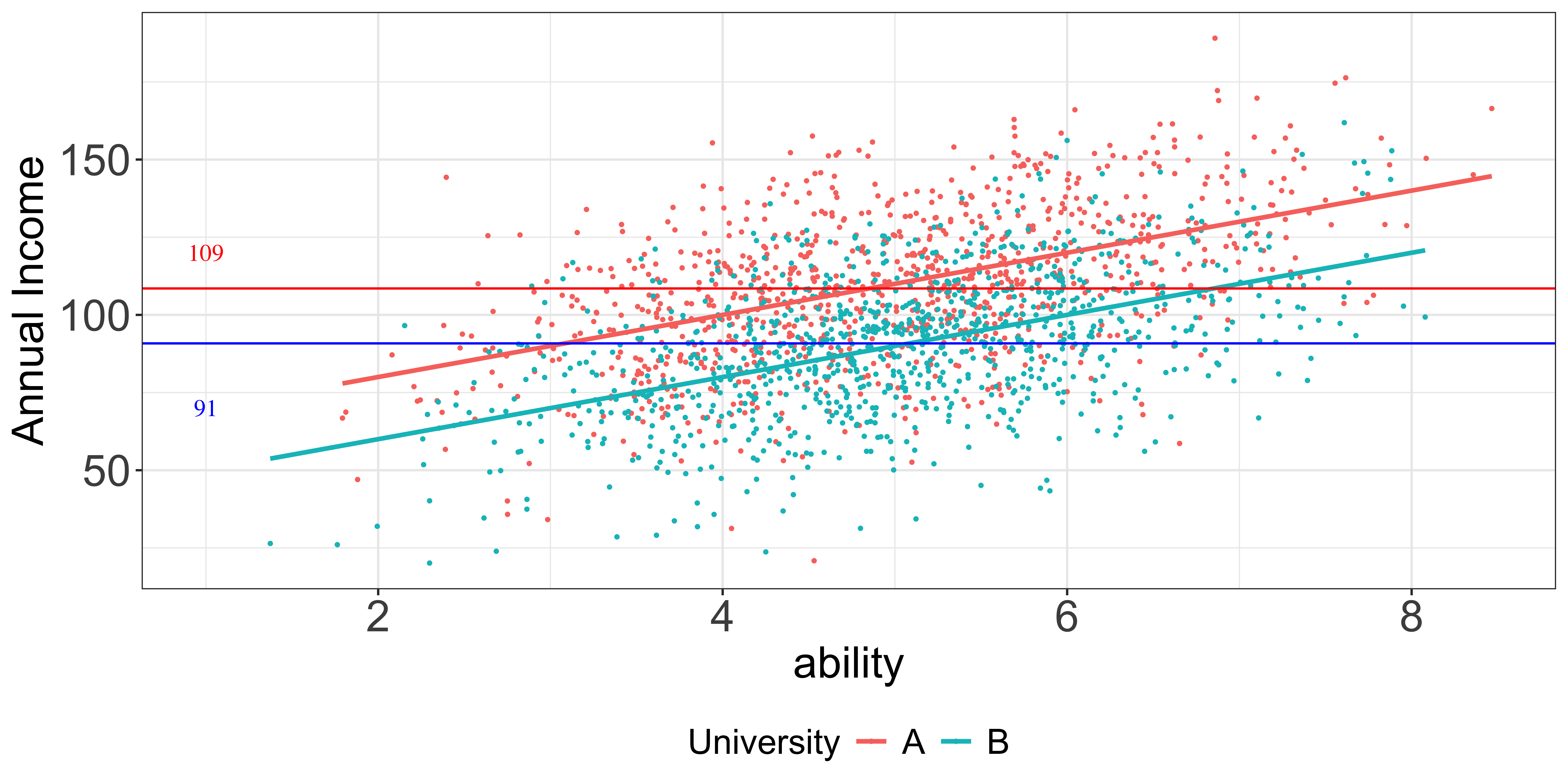
You have found the following data
University | average income | sample size |
|---|---|---|
A | 130.13 | 500 |
B | 90.13 | 500 |
Question
Should you assume that the observed difference of 40 is the expected boost you would get if you are to attend University A instead of B?
Let’s say your ability score is \(6\) out of \(10\) (the higher, the better),
\[\mbox{(1)}\;\; E[inc|A,ability=9] -E[inc|B,ability=6]\] \[\mbox{(2)}\;\; E[inc|A,ability=6] -E[inc|B,ability=6]\]
Which one would like you to know?
Going back to the college-income example
The model
\[ Income = \beta_0+\beta_1 College\;\; A + u \]
where \(College\;\; A\) is 1 if attending college A, 0 if attending college B, and \(u\) is the error term that includes ability. \(u\) includes ability.
Zero conditional mean satisfied?
\[ E[u(ability)|college A] = 0? \]
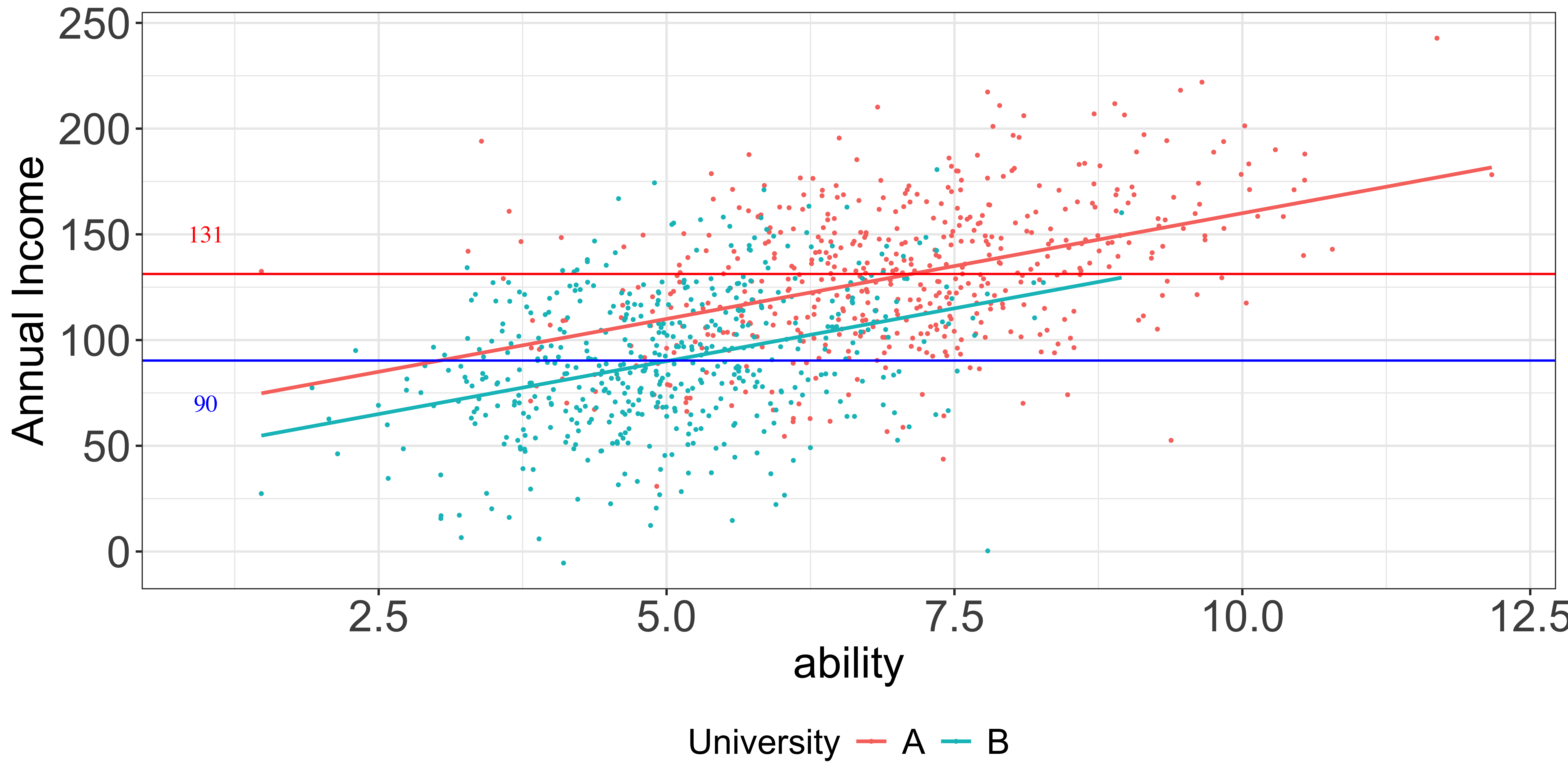
That is, are attending college A and ability (correlate) systematically related with each other? Or, is college choice (and acceptance of course) correlated with ability?
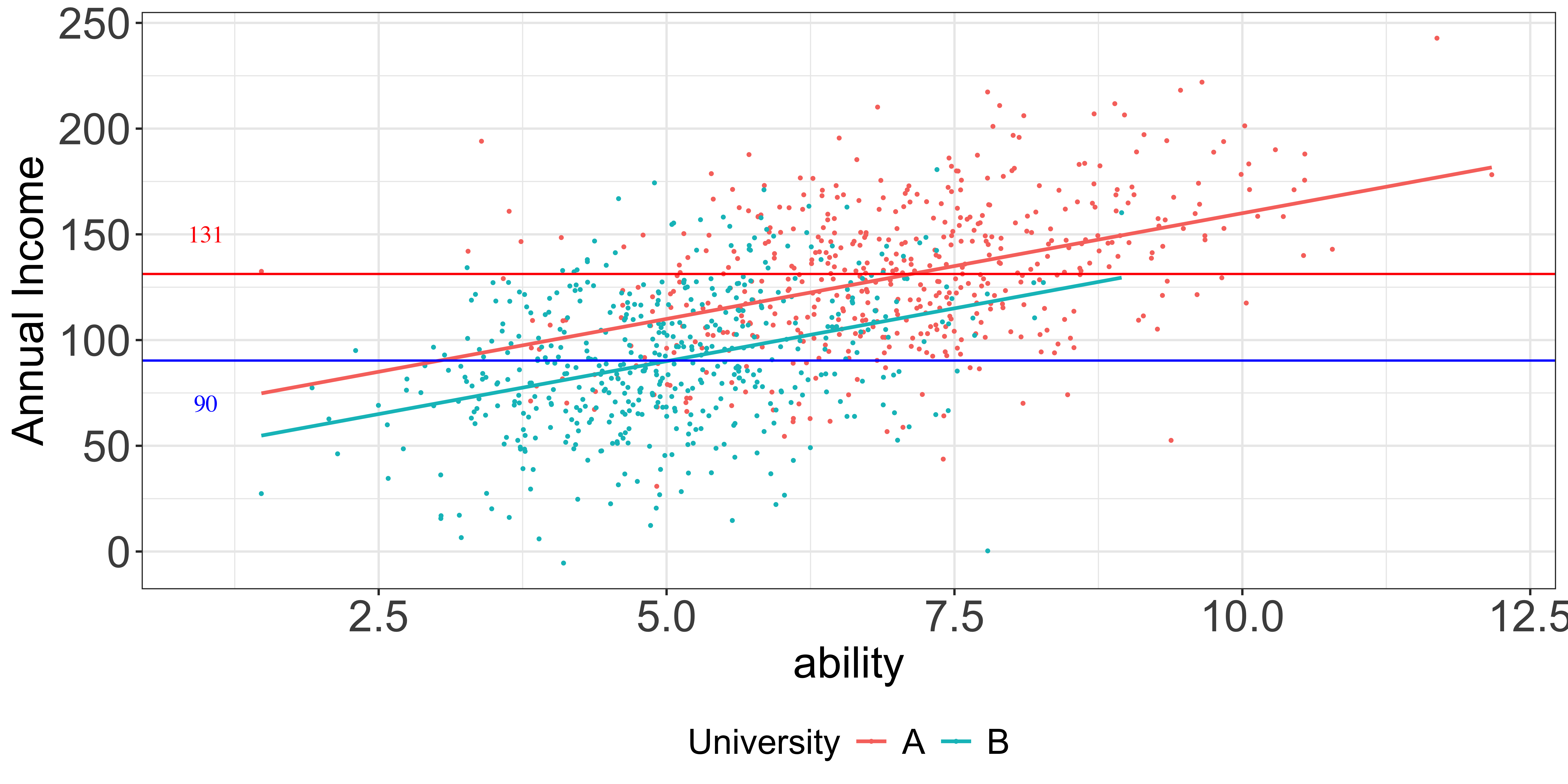
This is what it would like if college choice and ability are not correlated: